1 . 学校餐厅为了提升服务质量,更好地满足师生的用餐需求,餐厅调研员随机邀请了200名老师和同学对餐厅的用餐环境、菜品种类、菜品口味、营业时间进行评分,并采集评分数据。请运用所学内容,分析以下问题。
(1)适合餐厅调研员使用的数据采集方法是____________ (选填:问卷调查/传感数据采集)。
(3)整理后的数据存储于“T4_3.csv”文件中。编写程序求出综合评分的平均值,完成数据分析。以下选项填入划线处正确的是( ) 。
A.np.sum(score) B.np.mean(score) C.np.max(score) D.np.min(score)
(5)在撰写数据分析报告时,对可视化图形进行分析,无法从图中获得的结论是( ) 。
B.整体而言,学校餐厅菜品口味的好评度最高
C.学校餐厅可以增加菜品种类,提高师生的用餐满意度
D.师生普遍认为营业时间的设置不合理
(6)为了分析老师和同学对餐厅的整体评价,餐厅调研员将数据中综合评分60分及60分以上视为“合格”,60分以下视为“不合格”。请设计一个算法,统计“合格”与“不合格”的数量。选择合适的框图,将其拖至右侧流程图的虚线框内,将算法补充完整。_______________ ②_____________
(8)如图1所示完善输出内容的格式,运行该程序,出现图2所示的报错信息。请分析程序和报错信息,指出报错原因,并提出相应的修改方法。
图2
①报错原因:____________________
②修改方法:____________________
(1)适合餐厅调研员使用的数据采集方法是
(2)采集的评分数据存储于“T4_2.csv”文件中,如表所示是部分数据内容。针对红色框中数据存在的问题,运用合适的方法,将程序填写完整,完成数据整理。可以点击图标 进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。
进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。
数据编号 | 用餐环境评分 | 菜品种类评分 | 菜品口味评分 | 营业时间评分 | 综合评分 |
学生 1 | 88 | 69 | 94 | 89 | 85 |
学生 2 | 70 | 76 | 96 | 81 | 81 |
学生 3 | 80 | 73 | 91 | 89 | 83 |
学生 3 | 80 | 73 | 91 | 89 | 83 |
学生 3 | 80 | 73 | 91 | 89 | 83 |
学生 4 | 86 | 60 | 95 | 73 | 79 |
学生 5 | 90 | 75 | 99 | 83 | 87 |
学生 6 | 71 | 68 | 94 | 89 | 81 |
学生 7 | 70 | 51 | 70 | 52 | 61 |
…… | …… | …… | …… | …… | …… |
老师 6 | 94 | 85 | 92 | 70 | 85 |
老师 7 | 86 | 60 | 83 | 89 | 80 |
老师 7 | 86 | 60 | 83 | 89 | 80 |
…… | …… | …… | …… | …… | …… |
| import pandas as pd df=pd.read_csv("T4_2.csv",encoding="ANSI") mydf=① print(mydf) |
| import pandas as pd import numpy as np df=pd.read_csv("T4_3.csv",encoding="ANSI") # 获取综合评分数据 score=df["综合评分"] avg=①____ print(round(avg)) |
(4)根据如表所示的评分数据,绘制如图所示的可视化图形。请将程序填写完整,完成数据可视化,可以点击图标 进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。
进入开发环境,数据文件与程序位于同一文件夹目录,本题提供的环境仅用作算法验证。
数据编号 | 用餐环境评分 | 菜品种类评分 | 菜品口味评分 | 营业时间评分 | 综合评分 |
学生 1 | 88 | 69 | 94 | 89 | 85 |
学生 2 | 70 | 76 | 96 | 81 | 81 |
学生 3 | 80 | 73 | 91 | 89 | 83 |
学生 4 | 86 | 60 | 95 | 73 | 79 |
学生 5 | 90 | 75 | 99 | 83 | 87 |
学生 6 | 71 | 68 | 94 | 89 | 81 |
学生 7 | 70 | 51 | 70 | 52 | 61 |
学生 8 | 70 | 63 | 100 | 73 | 77 |
学生 9 | 92 | 82 | 77 | 80 | 83 |
…… | …… | …… | …… | …… | …… |
老师 1 | 76 | 61 | 94 | 76 | 77 |
老师 2 | 88 | 67 | 75 | 72 | 76 |
老师 3 | 92 | 82 | 80 | 71 | 81 |
…… | …… | …… | …… | …… | …… |

| import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] df=pd.read_csv("T4_4.csv",encoding="ANSI") items=["用餐环境评分","菜品种类评分","菜品口味评分","营业时间评分"] data1=df["用餐环境评分"] data2=df["菜品种类评分"] data3=df["菜品口味评分"] data4=df["营业时间评分"] plt.ylabel("分数") ① plt.show() |

B.整体而言,学校餐厅菜品口味的好评度最高
C.学校餐厅可以增加菜品种类,提高师生的用餐满意度
D.师生普遍认为营业时间的设置不合理
(6)为了分析老师和同学对餐厅的整体评价,餐厅调研员将数据中综合评分60分及60分以上视为“合格”,60分以下视为“不合格”。请设计一个算法,统计“合格”与“不合格”的数量。选择合适的框图,将其拖至右侧流程图的虚线框内,将算法补充完整。

(7)根据算法描述,编写程序统计“合格”与“不合格”的数量。请完善程序代码,将程序以原文件名保存在默认位置。点击图标 进入开发环境。
进入开发环境。
| # 根据算法描述,编写程序统计“合格”与“不合格”的数量 import pandas as pd df=pd.read_csv("T4_7.csv",encoding="ANSI") # 列表 score 中存放综合评分数据 score=list(df['综合评分']) # cnt1 用于统计“合格”的数量 cnt1=0 # cnt2 用于统计“不合格”的数量 cnt2=0 tot=len(score) # 在以下区域继续完善代码 # 以下输出语句,无需修改 print(cnt1,cnt2) # 根据测试源,判定结果(测试数据结果:195 5) |

| Traceback (most recent call last): File "C:\Users\admin\Desktop\T4_8. py", line 14, in <module> msg = "合格:" + cnt1 +",不合格:" + cnt2 |
①报错原因:
②修改方法:
您最近一年使用:0次
2 . 不同的室温会带来不同的人体感受度。例如,温度低于10℃,人体感觉冷;高于30℃,人体感觉热,在10℃~30℃之间时,人体感觉舒适。
为提醒人们适当增减衣物,办公室计划利用micro:bit开源硬件和Python语言开发一款室温提示设备,以“cold”、“hot”、“comfortable”的形式,显示室温环境。
micro:bit 代码:
请分析任务,完成下列题目。
(1)这款设备主要利用了( )
A.温度传感器 B.光线传感器 C.湿度传感器 D.加速度传感器
(2)为实现无限循环,在代码①处,应填写的内容是( )
A.0 B.True C.true D.无限次
(3)根据程序代码,传感器在该设备中的作用是( )
A.调节温度 B.获取温度 C.显示温度 D.控制循环
(4)根据程序代码,室温为26℃时,该设备显示的内容是( )
A.cold B.hot C.comfortable D.无显示
(5)若要滚动显示提示信息,应修改代码中的内容( )
A.将所有x修改为scroll B.将所有 temperature 修改为 scroll
C.将所有display修改为scroll D.将所有show修改为scroll
为提醒人们适当增减衣物,办公室计划利用micro:bit开源硬件和Python语言开发一款室温提示设备,以“cold”、“hot”、“comfortable”的形式,显示室温环境。
micro:bit 代码:
| from microbit import* while ① : x=temperature() if x<10: display.show("cold") elif x>30: display.show("hot") else: display.show("comfortable") |
(1)这款设备主要利用了
A.温度传感器 B.光线传感器 C.湿度传感器 D.加速度传感器
(2)为实现无限循环,在代码①处,应填写的内容是
A.0 B.True C.true D.无限次
(3)根据程序代码,传感器在该设备中的作用是
A.调节温度 B.获取温度 C.显示温度 D.控制循环
(4)根据程序代码,室温为26℃时,该设备显示的内容是
A.cold B.hot C.comfortable D.无显示
(5)若要滚动显示提示信息,应修改代码中的内容
A.将所有x修改为scroll B.将所有 temperature 修改为 scroll
C.将所有display修改为scroll D.将所有show修改为scroll
您最近一年使用:0次
3 . 小明喜欢看谍战片,对加密非常感兴趣,他想用Python语言设计一个加密程序,将输入的英文单词按照一定规律转换成另一段字符。
代码如下:
请分析任务,完成下列题目。
(1)程序代码中,①处应填写( )
A.all B.range C.between D.with
(2)程序代码中“x=len(str)”的作用是( )
A.为字符串赋值 B.将x转换为字符串
C.将字符串转换为x D.统计字符串的长度
(3)程序代码中,“y=ord(y)+3”实现的操作是( )
A.在提取字符的 ASCII 码值上加3 B.在提取字符的二进制值上加3
C.在提取字符的八进制值上加3 D.在提取字符的十六进制值上加3
(4)若小明输入的英文单词是“pen”,那么输出的结果会是( )
A.tir B.shq C.rgp D.mbk
(5)该程序属于程序设计结构中的( )
A.顺序结构 B.分支结构 C.循环结构 D.跳转结构
代码如下:
| str=input("请输入英文单词:") z="" x=len(str) for i in ① (0,x,1); y=str[i:i+1:] y=ord(y)+3 z=z+chr(y) print(z) |
(1)程序代码中,①处应填写
A.all B.range C.between D.with
(2)程序代码中“x=len(str)”的作用是
A.为字符串赋值 B.将x转换为字符串
C.将字符串转换为x D.统计字符串的长度
(3)程序代码中,“y=ord(y)+3”实现的操作是
A.在提取字符的 ASCII 码值上加3 B.在提取字符的二进制值上加3
C.在提取字符的八进制值上加3 D.在提取字符的十六进制值上加3
(4)若小明输入的英文单词是“pen”,那么输出的结果会是
A.tir B.shq C.rgp D.mbk
(5)该程序属于程序设计结构中的
A.顺序结构 B.分支结构 C.循环结构 D.跳转结构
您最近一年使用:0次
4 . 某大学“三位一体”综合评价招生的面试环节共有 n个类型的专业(编号为0~n-1)。由于报名学生较多,每个专业设立若干个面试考核组(学生只需要参加其中一个考核组面试)。每个学生只允许报名一个专业,按照“先到先面试”原则排队面试。假设每位学生都是面试考核结束再离开。当学生到达时,如果该专业前面没有学生,则无需等待直接面试;否则在门口排队等候。
现在,根据“interviewdata.txt”数据统计每个学生的等候时间。数据样例如图 a 所示,每行包含准考证号、到达或离开、专业类型、到达或离开时间4项,其中时间格式为HH:MM(表示小时:分)。程序的运行结果如图b所示。
请回答下列问题:
(1)面试学生到达或离开的数据如图a 所示,假设每个专业考核组数量均为1个,则学生1006的等待时间____ 分钟。
(2)定义如下readdata(file,a)函数,其中参数file表示数据文件名,参数a为列表用于存储数据,列表a的每个元素包含4项,准考证号、到达或离开、专业类型、到达或离开时间。该函数实现读取file文件数据,按时间从小到大排序,并返回列表a。请在划线处补充代码。
def readdata(file, a):
#读取文件中的数据并存储在列表 a 中,代码略
n = len(a)
for i in range(n - 1):
for j in range(n - i - 1):
if____ :
a[j], a[j + 1] = a[j + 1], a[j]
return a
(3)实现上述功能的部分 Python 程序如下,请在划线处填入合适的代码。
def cal(s): #将 HH: MM 转化为分钟
hours = int(s[0:2])
minutes = int(s[3:])
return hours * 60 + minutes
num =[]#存储每个专业的考核组数量
a = [ ]
#输入专业数量 m 和每个专业的考核组数量 num,代码略
a = readdata('interviewdata.txt', a)
queinfo =[[-1,-1] for i in range(m)] # 每个专业的队列头尾索引
q =[ ]
wait_times = {}# 存储每位学生的等待时间
for i in range(len(a)):
student_id = a[i][0]; status = a[i][1]
major = int(a[i][2]); time = cal (a[i][3])
if status == '离开':
num[major] += 1
if queinfo[major][0]!= -1:
①____
wait_times[q[head][0]] = time - q[head][1]
queinfo[major][0] = q[head][2] #更新队列头部
if queinfo[major][0] == -1:
queinfo[major][1] = -1
num[major] -= 1
else:
if num[major] > 0:
num[major] -= 1
②____
else:
node= [student_id, time, -1]
if queinfo[major][1] != -1:
③____
queinfo[major][1] = len(q)
if queinfo[major][0] == -1:
queinfo[major][0] = len(q)
q.append(node)
#输出每位学生的等待时间,代码略
现在,根据“interviewdata.txt”数据统计每个学生的等候时间。数据样例如图 a 所示,每行包含准考证号、到达或离开、专业类型、到达或离开时间4项,其中时间格式为HH:MM(表示小时:分)。程序的运行结果如图b所示。


请回答下列问题:
(1)面试学生到达或离开的数据如图a 所示,假设每个专业考核组数量均为1个,则学生1006的等待时间
(2)定义如下readdata(file,a)函数,其中参数file表示数据文件名,参数a为列表用于存储数据,列表a的每个元素包含4项,准考证号、到达或离开、专业类型、到达或离开时间。该函数实现读取file文件数据,按时间从小到大排序,并返回列表a。请在划线处补充代码。
def readdata(file, a):
#读取文件中的数据并存储在列表 a 中,代码略
n = len(a)
for i in range(n - 1):
for j in range(n - i - 1):
if
a[j], a[j + 1] = a[j + 1], a[j]
return a
(3)实现上述功能的部分 Python 程序如下,请在划线处填入合适的代码。
def cal(s): #将 HH: MM 转化为分钟
hours = int(s[0:2])
minutes = int(s[3:])
return hours * 60 + minutes
num =[]#存储每个专业的考核组数量
a = [ ]
#输入专业数量 m 和每个专业的考核组数量 num,代码略
a = readdata('interviewdata.txt', a)
queinfo =[[-1,-1] for i in range(m)] # 每个专业的队列头尾索引
q =[ ]
wait_times = {}# 存储每位学生的等待时间
for i in range(len(a)):
student_id = a[i][0]; status = a[i][1]
major = int(a[i][2]); time = cal (a[i][3])
if status == '离开':
num[major] += 1
if queinfo[major][0]!= -1:
①
wait_times[q[head][0]] = time - q[head][1]
queinfo[major][0] = q[head][2] #更新队列头部
if queinfo[major][0] == -1:
queinfo[major][1] = -1
num[major] -= 1
else:
if num[major] > 0:
num[major] -= 1
②
else:
node= [student_id, time, -1]
if queinfo[major][1] != -1:
③
queinfo[major][1] = len(q)
if queinfo[major][0] == -1:
queinfo[major][0] = len(q)
q.append(node)
#输出每位学生的等待时间,代码略
您最近一年使用:0次
5 . 提取数字字符串中以逗号分隔的数字并转换为整数存入数组,再将数组中的元素进行分类,第一类为“小于30”;第二类为“30-60";第三类为“大于60”。例如输入数字字符串为“34,23,45,99,24,56,9,87,”,输出结果为[23,9,24][34,45,56][87,99]。
(1)实现上述功能的Python程序段如下,请在划线处填入合适的代码。
s=input("请输入字符串(数字之间用逗号分隔):")
ch="";a=[]
for i in range(len(s)):
if s[i]!=",":
ch+=s[i]
if s[i]=","or i=len(s)-1:
a.append(int(ch))
①____
i=0;j=len(a)-1;k=0
while k<=j:
if ②____ :
a[i],a[k]=a[k],a[i]
i+=1
elif a[k]>60:
a[k],a[j]=a[j],a[k]
j-=1
③____
k+=1
print(a[:i],a[i:j+1],a[j+1:])
(2)若两组输入的数据分别为"12,78,65,7,45,2,55,"、"12,78,65,7,45,2,55",则两组输出的结果____ (单选,填字母:A.一致;B.不一致)
(1)实现上述功能的Python程序段如下,请在划线处填入合适的代码。
s=input("请输入字符串(数字之间用逗号分隔):")
ch="";a=[]
for i in range(len(s)):
if s[i]!=",":
ch+=s[i]
if s[i]=","or i=len(s)-1:
a.append(int(ch))
①
i=0;j=len(a)-1;k=0
while k<=j:
if ②
a[i],a[k]=a[k],a[i]
i+=1
elif a[k]>60:
a[k],a[j]=a[j],a[k]
j-=1
③
k+=1
print(a[:i],a[i:j+1],a[j+1:])
(2)若两组输入的数据分别为"12,78,65,7,45,2,55,"、"12,78,65,7,45,2,55",则两组输出的结果
您最近一年使用:0次
6 . 小明想研制一种药物,他采集了n种原料,现需要对每种原料的成分进行精密的分析。每种原料的分析都必须依次经过两个步骤:先进行放射试验,再进行加热试验。因为实验室里只有一台放射试验仪器和一台加热试验仪器,所以,同一时间最多只能做一个放射试验和一个加热试验。为尽早完成试验,小明将放射试验用时短的尽量排前面,加热试验时间用时短的尽量排后面。
例如:有A~E共5种原料,每种原料需要的试验时间如图1所示;最终各原料的试验安排如图2所示。
图1
编写程序:给定各种原料所需试验的时间,根据上述方法安排试验顺序并计算所有原料完成试验的最早结束时间,输出结果如图3所示。
(1)自定义函数order(task,n)的功能是安排合理的试验顺序,使得试验尽早完成。其中参数task的每个元素由原料名称、放射时间和加热时间3个数据项构成,参数n为原料种类。
def order(task,n):
f=[False]*n
st=-1;ed=n
for j in range(n):
if f[j]==False:
for k in range(1,3):
if task[j][k] < min:
min=task[j][k]
bestj=j
bestk=k
if bestk==1:
st+=1;odr[st]=bestj
else:
ed-=1;odr[ed]=bestj
若task=[['A',5,2],['B',4,2],['C',1,8]],n=3,请回答下列问题。
①调用该函数后,st和ed的值分别为____ ,____ 。
②将虚线框处代码改成for j in range(n-1,-1,-1),是否会影响原料试验的安排顺序?____ (单选,填字母:A.会;B.不会)
③上述程序中,划线处应填入的正确代码是____
(2)实现程序功能的部分代码如下,请在划线处填上合适的代码。
def CalTime0:
tm=[0]*n#各原料完成放射试验的结束时间
tm[0]=task[odr[0]][1]
for i in range(1,n):
①____
tot=0
for i in range(n):
j=odr[i]
if tot>tm[i]:
②____
else:
tot=tm[i]+task[j][2]
return tot
```
读取原料试验数据,并存入列表task。task[i]包含3个数据项,task[i][0]、task[i][1]、task[i][2]分别存放该原料的名称、放射试验和加热试验的单位时间量,代码略
如task=[['A',8,5],['B',4,2],['C',4,10],['D',16,7],['E',3,5]]
```
n=len(task)
odr=[-1]*n
order(task,n)
#输出所有原料的试验顺序,如图3,代码略
print("结束试验的最早时间:",CalTime())
例如:有A~E共5种原料,每种原料需要的试验时间如图1所示;最终各原料的试验安排如图2所示。
| 原料名称 | 放射试验时间 | 加热试验时间 |
| A | 8 | 5 |
| B | 4 | 2 |
| C | 4 | 10 |
| D | 16 | 7 |
| E | 3 | 5 |
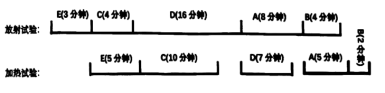

编写程序:给定各种原料所需试验的时间,根据上述方法安排试验顺序并计算所有原料完成试验的最早结束时间,输出结果如图3所示。
(1)自定义函数order(task,n)的功能是安排合理的试验顺序,使得试验尽早完成。其中参数task的每个元素由原料名称、放射时间和加热时间3个数据项构成,参数n为原料种类。
def order(task,n):
f=[False]*n
st=-1;ed=n

for j in range(n):
if f[j]==False:
for k in range(1,3):
if task[j][k] < min:
min=task[j][k]
bestj=j
bestk=k
if bestk==1:
st+=1;odr[st]=bestj
else:
ed-=1;odr[ed]=bestj
若task=[['A',5,2],['B',4,2],['C',1,8]],n=3,请回答下列问题。
①调用该函数后,st和ed的值分别为
②将虚线框处代码改成for j in range(n-1,-1,-1),是否会影响原料试验的安排顺序?
③上述程序中,划线处应填入的正确代码是
(2)实现程序功能的部分代码如下,请在划线处填上合适的代码。
def CalTime0:
tm=[0]*n#各原料完成放射试验的结束时间
tm[0]=task[odr[0]][1]
for i in range(1,n):
①
tot=0
for i in range(n):
j=odr[i]
if tot>tm[i]:
②
else:
tot=tm[i]+task[j][2]
return tot
```
读取原料试验数据,并存入列表task。task[i]包含3个数据项,task[i][0]、task[i][1]、task[i][2]分别存放该原料的名称、放射试验和加热试验的单位时间量,代码略
如task=[['A',8,5],['B',4,2],['C',4,10],['D',16,7],['E',3,5]]
```
n=len(task)
odr=[-1]*n
order(task,n)
#输出所有原料的试验顺序,如图3,代码略
print("结束试验的最早时间:",CalTime())
您最近一年使用:0次
7 . 第19届杭州亚运会已完美落幕,亚运会赛事以“杭州为主,全省共享”的原则分布在杭州、宁波、温州、湖州、绍兴、金华各地。大会共有40个大项,61个分项,最终诞生了481块金牌。小李作为一名体育爱好者想重温大会赛程安排,他从杭州亚运会的官网上采集了相关数据,整理后存储在“杭州第19届亚运会总赛程.x1sx”文件中。如图a所示(0表示有赛事但不产生金牌,其他数字表示当天产生的金牌数)。
为了更清楚地了解相关赛事信息,小李编写了Python程序,请回答以下问题。
(1)足球是小李最关注的大项,为了解足球的赛程安排,划线处应填入的代码为____ (单选,填字母)
A.df.大项=="足球" B.df["大项"=="足球"] C.df[df.大项=="足球"] D.df[df["大项"==足球]
import pandas as pd
df=pd.read_excel("杭州第19届亚运会总赛程.xlsx")
df2=
print(df2)
(2)足球项目的比赛分布在杭州等城市的八个场馆,了解各个场馆举办足球赛事的具体场次,找到连续举办足球赛事最多的场馆,如图b所示。程序代码如下,请在划线处填入合适的代码。
dic={};max=0;maxsta=""
1st=df2.竞赛场馆.tolist()
#将数据转换为列表
for i in lst:
dic[i]=[]
for i in df2.index:
c=0
sta=df2["竞赛场馆"][i]
for j in df2.columns[2:-3]:
if df2.at[i,j]==0 or df2.at[i,j]=1
①____
c=c+1
if c>max:
max=c;maxsta=sta
else:
②____
for i in dic:
print(i,dic[i])
print("连续举办足球赛事最多的场馆:",maxsta)
(3)足球在亚运会期间总共产生两枚金牌,统计分析其他大项产生的金牌总数,找出产生金牌总数最多的十个大项,并绘制图形如图c所示。程序代码如下,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei'] #图表中文标签显示为黑体
grp=df.groupby(①____ ,as-index=False),金牌总数.sum()
grp=grp.sort_values("金牌总数",ascending=False).②____
x=grp.大项
y=grp.金牌总数
plt.figure(figsize=(6,4))
plt,title("金牌总数前十的大项")
plt.xlabel("大项")
plt.ylabel("金牌总数")
plt.bar(x,y)
plt.show()
为了更清楚地了解相关赛事信息,小李编写了Python程序,请回答以下问题。
(1)足球是小李最关注的大项,为了解足球的赛程安排,划线处应填入的代码为
A.df.大项=="足球" B.df["大项"=="足球"] C.df[df.大项=="足球"] D.df[df["大项"==足球]
import pandas as pd
df=pd.read_excel("杭州第19届亚运会总赛程.xlsx")
df2=
print(df2)
(2)足球项目的比赛分布在杭州等城市的八个场馆,了解各个场馆举办足球赛事的具体场次,找到连续举办足球赛事最多的场馆,如图b所示。程序代码如下,请在划线处填入合适的代码。

dic={};max=0;maxsta=""
1st=df2.竞赛场馆.tolist()
#将数据转换为列表
for i in lst:
dic[i]=[]
for i in df2.index:
c=0
sta=df2["竞赛场馆"][i]
for j in df2.columns[2:-3]:
if df2.at[i,j]==0 or df2.at[i,j]=1
①
c=c+1
if c>max:
max=c;maxsta=sta
else:
②
for i in dic:
print(i,dic[i])
print("连续举办足球赛事最多的场馆:",maxsta)
(3)足球在亚运会期间总共产生两枚金牌,统计分析其他大项产生的金牌总数,找出产生金牌总数最多的十个大项,并绘制图形如图c所示。程序代码如下,请在划线处填入合适的代码。
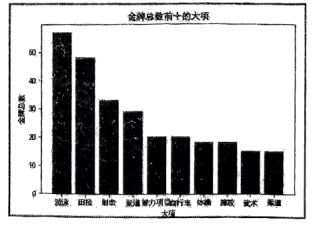
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['simhei'] #图表中文标签显示为黑体
grp=df.groupby(①
grp=grp.sort_values("金牌总数",ascending=False).②
x=grp.大项
y=grp.金牌总数
plt.figure(figsize=(6,4))
plt,title("金牌总数前十的大项")
plt.xlabel("大项")
plt.ylabel("金牌总数")
plt.bar(x,y)
plt.show()
您最近一年使用:0次
8 . 小明要搭建一个空气质量监测系统,该系统能实现监测周围环境的PM2.5浓度值,当浓度值大于阈值时发出警报。用户通过浏览器查看实时监测的数据和历史数据。该系统结构示意图如图1所示,传感器采集的数据由智能终端经IOT模块发送给Web服务器,并存储在数据库中。执行器用于实现数据异常时的报警功能。请回答下列问题:
(1)关于该空气质量监测系统及其搭建,下面说法不正确的是____ (多选,填字母)。
A.该系统采集的实时数据可为用户的健康出行做参考,具有较好的社会意义
B.该系统采用B/S架构,用户需安装专门的程序才能访问该系统
C.该系统可以同时为多个用户提供数据查询服务
D.必须所有硬件搭建完成后,才能进行服务器端的程序编写
(2)服务器端获取来自智能终端提交的数据并进行相应处理,部分代码如下:
#导入相关模块,代码略
app=Flask(name_)
@app.route("/input")
def add_data():
#从数据库中获取阈值,保存在h中,代码略
pm_value=int(request.args.get("d"))
#将pm_value的值存入数据库,代码略
if pm_value>h:
return "0"
else:
return "1"
①智能终端将采集到的PM2.5浓度数据保存在变量data中,提交数据到Web服务器的URL为http://192.168.35.1:8000/input?d=data,则响应该URL请求的Web服务器IP地址为____ ,服务器中视图函数____ (填写函数名称)的代码会被运行。
2智能终端在接收到来自服务器返回的数据“1”时,需要给执行器发送指令实现_________ (单选,填字母:A.开启执行器发出警报;B.关闭执行器停止警报)
(3)系统正常运行一段时间后,用户通过浏览器查看到实时数据超过阈值时,系统却没有发出警报,造成这个问题的可能原因是(写两项):____ 。
(4)小明将系统中2023年的所有PM2.5浓度值导出,进行预处理后,得到如图2所示的数据(日期格式为“年-月-日”),编写程序分析每个月空气中PM2.5浓度为“合格”的情况(PM2.5浓度值不超过75表示“合格”,否则为“不合格”)。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("2023年.xlsx")
df.insert(0,"月份","") #插入列
for i in df.index:
t=df.at[i,"日期"] #通过行标签和列标签选取单个值
df.at[i,"月份"]-t[5:7]
x=df2["月份"]
y-df2["PM2.5"]
plt.bar(x,y)#绘制柱形图
#设置绘图参数,显示如图3所示的柱形图,代码略
①方框处的代码实现统计每个月PM2.5指标为合格的总天数,下面代码能实现该功能的是____ (单选,填字母)
A.dfl=df.groupby("月份",as_index=False).count()
df2=dfl[df1["PM2.5"]<=75]
B.dfl=df[df["PM2.5"]<=75]
df2=df.groupby("月份",as_index=False).count()
C.dfl=df[df["PM2.5"]<=75]
df2=dfl.groupby("月份",as_index=False).sum()
D.dfl=df[df["PM2.5"]<=75]
df2=dfi.groupby("月份",as_index=False).count()
②小明分析图3发现,PM2.5浓度值为“合格”的天数最少的是____ 月份,并建议公众在该月份做好健康防护工作。
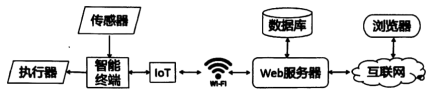
(1)关于该空气质量监测系统及其搭建,下面说法不正确的是
A.该系统采集的实时数据可为用户的健康出行做参考,具有较好的社会意义
B.该系统采用B/S架构,用户需安装专门的程序才能访问该系统
C.该系统可以同时为多个用户提供数据查询服务
D.必须所有硬件搭建完成后,才能进行服务器端的程序编写
(2)服务器端获取来自智能终端提交的数据并进行相应处理,部分代码如下:
#导入相关模块,代码略
app=Flask(name_)
@app.route("/input")
def add_data():
#从数据库中获取阈值,保存在h中,代码略
pm_value=int(request.args.get("d"))
#将pm_value的值存入数据库,代码略
if pm_value>h:
return "0"
else:
return "1"
①智能终端将采集到的PM2.5浓度数据保存在变量data中,提交数据到Web服务器的URL为http://192.168.35.1:8000/input?d=data,则响应该URL请求的Web服务器IP地址为
2智能终端在接收到来自服务器返回的数据“1”时,需要给执行器发送指令实现
(3)系统正常运行一段时间后,用户通过浏览器查看到实时数据超过阈值时,系统却没有发出警报,造成这个问题的可能原因是(写两项):
(4)小明将系统中2023年的所有PM2.5浓度值导出,进行预处理后,得到如图2所示的数据(日期格式为“年-月-日”),编写程序分析每个月空气中PM2.5浓度为“合格”的情况(PM2.5浓度值不超过75表示“合格”,否则为“不合格”)。

import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("2023年.xlsx")
df.insert(0,"月份","") #插入列
for i in df.index:
t=df.at[i,"日期"] #通过行标签和列标签选取单个值
df.at[i,"月份"]-t[5:7]
y-df2["PM2.5"]
plt.bar(x,y)#绘制柱形图
#设置绘图参数,显示如图3所示的柱形图,代码略
①方框处的代码实现统计每个月PM2.5指标为合格的总天数,下面代码能实现该功能的是
A.dfl=df.groupby("月份",as_index=False).count()
df2=dfl[df1["PM2.5"]<=75]
B.dfl=df[df["PM2.5"]<=75]
df2=df.groupby("月份",as_index=False).count()
C.dfl=df[df["PM2.5"]<=75]
df2=dfl.groupby("月份",as_index=False).sum()
D.dfl=df[df["PM2.5"]<=75]
df2=dfi.groupby("月份",as_index=False).count()
②小明分析图3发现,PM2.5浓度值为“合格”的天数最少的是
您最近一年使用:0次
名校
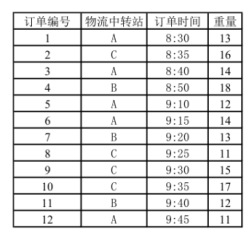
9 . 某水果店铺每天接收来自全国各地的订单如图a所示,为了保证水果的新鲜程度和提高顾客的购物体验,店铺每天下午四点前的订单必须当天全部发出送往附近三个物流中转站ABC,再经由中转站发往全国各地。店铺按照订单顺序打包,相同地区的包裹装在一起,当某一地区包裹总重量超过货车限重m时,则将已有包裹按照时间顺序装多辆车运走,同一辆车按重量从大到小放置包裹。编写程序,按送达顺序将包裹装车,输出各车次及对应的订单编号,运行结果如图b所示。
(1)若货车限重升级为60,则如图a所示的订单需要发送的车次数量为____
(2)实现上述功能的部分Python程序如下,请在划线处填入合适的代码。
def loading(k,num): # 已送达待打包的物品按重量由大到小输出
num+=1
p=tot[k][1]
k=chr(65+k)
print("第"+str(num)+"车,发往中转站"+k+",各包裹订单号为:",end=" ")
return num
'''接收到的订单数据储存在数组orders中,orders中节点包含信息[订单编号,物流中转站,订单时间,重量],货车限重为 m,代码略'''
n=len(orders)
m=40
num=0
for i in range(len(orders)):
order[i].append(-1)
tot=[[0,-1] for i in range(3)]
for i in range(n):
k=ord(orders[i][1])-65
if tot[k][0]+orders[i][3]>m:
num=loading(k,num)
tot[k]=[0,-1]
①____
if p==-1:
tot[k][1]=i
else:
if orders[i][3]>orders[p][3]:
tot[k][1]=i
else:
q=-1
while ②____ :
q=p
p=orders[p][4]
orders[q][4]=i
orders[i][4]=p
③____
#重量不足 m 的剩余包裹,按照物流中转站依次装入货车
for i in range(3):
if tot[i][1]!=-1:
num=loading(i,num)
(3)加框处代码替换为下列的____ (多选,填写字母),仍能实现上述功能。

(1)若货车限重升级为60,则如图a所示的订单需要发送的车次数量为
(2)实现上述功能的部分Python程序如下,请在划线处填入合适的代码。
def loading(k,num): # 已送达待打包的物品按重量由大到小输出
num+=1
p=tot[k][1]
k=chr(65+k)
print("第"+str(num)+"车,发往中转站"+k+",各包裹订单号为:",end=" ")
| while orders[p][4]!=-1: print(orders[p][0],end=" ") p=orders[p][4] print(orders[p][0]) |
'''接收到的订单数据储存在数组orders中,orders中节点包含信息[订单编号,物流中转站,订单时间,重量],货车限重为 m,代码略'''
n=len(orders)
m=40
num=0
for i in range(len(orders)):
order[i].append(-1)
tot=[[0,-1] for i in range(3)]
for i in range(n):
k=ord(orders[i][1])-65
if tot[k][0]+orders[i][3]>m:
num=loading(k,num)
tot[k]=[0,-1]
①
if p==-1:
tot[k][1]=i
else:
if orders[i][3]>orders[p][3]:
tot[k][1]=i
else:
q=-1
while ②
q=p
p=orders[p][4]
orders[q][4]=i
orders[i][4]=p
③
#重量不足 m 的剩余包裹,按照物流中转站依次装入货车
for i in range(3):
if tot[i][1]!=-1:
num=loading(i,num)
(3)加框处代码替换为下列的
| A. while p!=-1: print(orders[p][0],end=" ") p=orders[p][4] print() | B. q=p p=orders[p][4] while p!=-1: print(orders[p][0],end=" ") q=p p=orders[p][4] print() |
| C. while orders[p][4]!=-1: print(orders[orders[p][4]][0],end=" ") p=orders[p][4] print() | D. q=p p=orders[p][4] while p!=-1: print(orders[q][0],end=" ") q=p p=orders[p][4] print(orders[q][0]) |
您最近一年使用:0次
名校
10 . 丑数是指不能被2,3,5以外的其他素数整除的数。例如6和8都是丑数,但7和14都不是丑数,因为它们包含了质因子7。习惯上,1被当作第一个丑数,前8个丑数分别为:1,2,3,4,5,6,8,9。小林对丑数非常感兴趣,为此他设计了一个能够查找用户输入的数字中的最大丑数以及次大丑数的程序。
请回答下列问题:
(1)实现上述功能的部分Python程序如下,请在划线处填入合适的代码。
def isUglyNum(n):
while n % 2 == 0:
n = n // 2
while n % 3 == 0:
n = n // 3
while n % 5 == 0:
n = n // 5
return ①____
s = input("请输入正整数(数字之间用逗号隔开):")
mx1 = mx2 = -1
tmp = 0
s += ","
for i in s:
if i != ",":
tmp =②____
else:
if isUglyNum(tmp):
if tmp > mx1:
③____
mx1 = tmp
elif tmp > mx2:
mx2 = tmp
tmp = 0
if mx1 == -1:
print("序列中没有丑数")
elif mx2 == -1:
print("最大丑数为:" + str(mx1))
else:
print("最大丑数为:" + str(mx1) + ";次大丑数为:" + str(mx2))
(2)输入"6,7,8,9,10,11,12"后,mx1与mx2的值分别为____ 。
请回答下列问题:
(1)实现上述功能的部分Python程序如下,请在划线处填入合适的代码。
def isUglyNum(n):
while n % 2 == 0:
n = n // 2
while n % 3 == 0:
n = n // 3
while n % 5 == 0:
n = n // 5
return ①
s = input("请输入正整数(数字之间用逗号隔开):")
mx1 = mx2 = -1
tmp = 0
s += ","
for i in s:
if i != ",":
tmp =②
else:
if isUglyNum(tmp):
if tmp > mx1:
③
mx1 = tmp
elif tmp > mx2:
mx2 = tmp
tmp = 0
if mx1 == -1:
print("序列中没有丑数")
elif mx2 == -1:
print("最大丑数为:" + str(mx1))
else:
print("最大丑数为:" + str(mx1) + ";次大丑数为:" + str(mx2))
(2)输入"6,7,8,9,10,11,12"后,mx1与mx2的值分别为
您最近一年使用:0次


