名校
1 . 为了加深师生对党史的了解,激发广大师生知史爱党、知史爱国的热情,某校举办了“学党史、育文化”的党史知识竞赛,并将1000名师生的竞赞成绩(满分100分,成绩取整数)整理成如图所示的频率分布直方图,估计这组数据的第85百分位数为( )分

| A.84 | B.85 | C.86 | D.87 |
您最近一年使用:0次
名校
2 . 某校高三共有200人参加体育测试,将体测得分情况进行了统计,把得分数据按照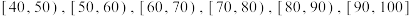 分成6组,绘制了如图所示的频率分布直方图.根据规则,82分以上的考生成绩等级为A,则获得
分成6组,绘制了如图所示的频率分布直方图.根据规则,82分以上的考生成绩等级为A,则获得 的考生人数约为( )
的考生人数约为( )
分成6组,绘制了如图所示的频率分布直方图.根据规则,82分以上的考生成绩等级为A,则获得的考生人数约为( )
| A.25 | B.50 | C.75 | D.100 |
您最近一年使用:0次
3 . 2023年7月31日国家统计局发布了制造业采购经理指数(PMI)如下图所示:
①从2022年7月到2023年7月,这13个月的PMI的极差为5.6%;
②PMI大于50%,表示经济处于扩张活跃的状态,PMI小于50%,表示经济处于低迷萎缩的状态,则2023年1月到2023年3月,经济处于扩张活跃的状态;
③从2023年1月到2023年7月,这7个月的PMI的第75百分位数为51.9%;
④2023年7月份,PMI为49.3%,比上月上升0.3个百分点.
其中正确的有( )
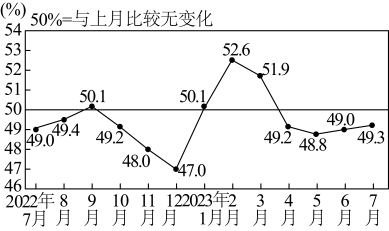
①从2022年7月到2023年7月,这13个月的PMI的极差为5.6%;
②PMI大于50%,表示经济处于扩张活跃的状态,PMI小于50%,表示经济处于低迷萎缩的状态,则2023年1月到2023年3月,经济处于扩张活跃的状态;
③从2023年1月到2023年7月,这7个月的PMI的第75百分位数为51.9%;
④2023年7月份,PMI为49.3%,比上月上升0.3个百分点.
其中正确的有( )
| A.1个 | B.2个 | C.3个 | D.4个 |
您最近一年使用:0次
名校
4 . 下列说法正确的是( )
A.一组数据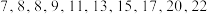 的第80百分位数为17; 的第80百分位数为17; |
B.根据分类变量 与 与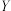 的成对样本数据,计算得到 的成对样本数据,计算得到 ,根据小概率值 ,根据小概率值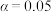 的独立性检验 的独立性检验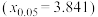 ,可判断与有关联,此推断犯错误的概率不大于0.05; ,可判断与有关联,此推断犯错误的概率不大于0.05; |
| C.两个随机变量的线性相关性越强,相关系数的绝对值越接近于0; |
D.若随机变量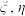 满足 满足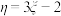 ,则 ,则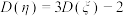 . . |
您最近一年使用:0次
2024-03-29更新
|
1353次组卷
|
3卷引用:天津市十二区重点学校2023-2024学年高三下学期毕业班联考(一)数学试题(滨海新区2024届高三第一次模拟考试数学试卷)
解题方法
5 . 根据《中华人民共和国道路交通安全法》规定:血液酒精浓度在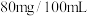 (含80)以上时,属醉酒驾车,处十五日以下拘留和三个月以上六个月以下暂扣驾驶证,并处500元以上2000元以下罚款,某地统计了近五年来查处的酒后驾车和醉酒驾车共200人,如图,这是对这200人酒后驾车血液中酒精含量进行检测所得结果的频率分布直方图,下列说法正确的是( )
(含80)以上时,属醉酒驾车,处十五日以下拘留和三个月以上六个月以下暂扣驾驶证,并处500元以上2000元以下罚款,某地统计了近五年来查处的酒后驾车和醉酒驾车共200人,如图,这是对这200人酒后驾车血液中酒精含量进行检测所得结果的频率分布直方图,下列说法正确的是( )
(含80)以上时,属醉酒驾车,处十五日以下拘留和三个月以上六个月以下暂扣驾驶证,并处500元以上2000元以下罚款,某地统计了近五年来查处的酒后驾车和醉酒驾车共200人,如图,这是对这200人酒后驾车血液中酒精含量进行检测所得结果的频率分布直方图,下列说法正确的是( ) 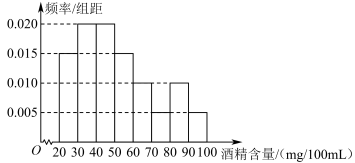
| A.在酒后驾车的驾驶人中醉酒驾车比例不高因此危害不大 |
| B.在频率分布直方图中每个柱的高度代表区间内人数的频率 |
| C.根据频率分布直方图可知200人中醉酒驾车的约有30人 |
D.这200人酒后驾车血液中酒精含量的平均值约为 |
您最近一年使用:0次
解题方法
6 . 下列说法不正确的是( )
A.若随机变量服从正态分布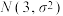 ,且 ,且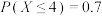 ,则 ,则 |
| B.一组数据10,11,11,12,13,14,16,18,20,22的第60百分位数为14 |
C.若线性相关系数 越接近1,则两个变量的线性相关性越强 越接近1,则两个变量的线性相关性越强 |
D.对具有线性相关关系的变量x,y,且线性回归方程为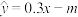 ,若样本点的中心为 ,若样本点的中心为 ,则实数 ,则实数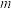 的值是 的值是 |
您最近一年使用:0次
名校
7 . 党的二十大报告提出,要加快发展数字经济,促进数字经济与实体经济的深度融合,数字化构建社区服务新模式成为一种时尚.某社区为优化数字化社区服务,问卷调查调研数字化社区服务的满意度,满意度采用计分制(满分100分),统计满意度绘制成如下频率分布直方图,图中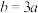 .则下列结论不正确的是( )
.则下列结论不正确的是( )
.则下列结论不正确的是( )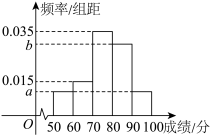
A.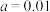 | B.满意度计分的众数为80分 |
C.满意度计分的 分位数是85分 分位数是85分 | D.满意度计分的平均分是76.5 |
您最近一年使用:0次
8 . 2023年7月28日,第31届世界大学生夏季运动会(简称大运会)在四川成都开幕,这是继2001北京大运会,2011深圳大运会之后,中国第三次举办夏季大运会;在成都大运会中,中国代表团取得了骄人的成绩.为向大学生普及大运会的相关知识,某高校进行“大运会知识竞赛”,并随机从中抽取了200名学生的成绩(满分100分)进行统计,成绩均在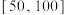 内,将其分成5组:
内,将其分成5组: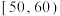 ,
,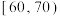 ,
,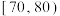 ,
,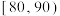 ,
,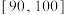 ,并整理得到如下的频率分布直方图,则在被抽取的学生中,成绩落在区间内的人数为( )
,并整理得到如下的频率分布直方图,则在被抽取的学生中,成绩落在区间内的人数为( )
内,将其分成5组:,,,,,并整理得到如下的频率分布直方图,则在被抽取的学生中,成绩落在区间内的人数为( )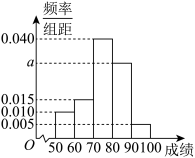
| A.20 | B.40 | C.60 | D.80 |
您最近一年使用:0次
9 . 树人中学跨学科项目式研学小组的同学们准备研究高一年级新生的健康情况.他们从学校医务室得到高一年级学生身高的所有数据,计算出整个年级学生的平均身高为 .然后,同学们用简单随机抽样的方法,从这些数据中抽取了样本量为50和100的样本各10个,分别计算出样本平均数,如下表.
.然后,同学们用简单随机抽样的方法,从这些数据中抽取了样本量为50和100的样本各10个,分别计算出样本平均数,如下表.
为了更方便地观察数据,以便我们分析样本平均数的特点以及与总体平均数的关系,我们把这20次试验的平均数用图形表示出来,如下图所示
.然后,同学们用简单随机抽样的方法,从这些数据中抽取了样本量为50和100的样本各10个,分别计算出样本平均数,如下表.| 抽样序号 | ||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 样本量为50的平均数 | 165.2 | 162.8 | 164.4 | 164.4 | 165.6 | 164.8 | 165.3 | 164.7 | 165.7 | 165.0 |
| 样本量为100的平均数 | 164.4 | 165.0 | 164.7 | 164.9 | 164.6 | 164.9 | 165.1 | 165.2 | 165.1 | 165.2 |
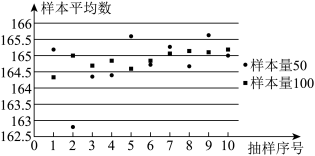
| A.1 | B.2 | C.3 | D.4 |
您最近一年使用:0次
10 . 已知甲乙两组数据分别为 和
和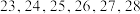 ,则下列说法中不正确的是( )
,则下列说法中不正确的是( )
和,则下列说法中不正确的是( )| A.甲组数据中第70百分位数为23 | B.甲乙两组数据的极差相同 |
| C.乙组数据的中位数为25.5 | D.甲乙两组数据的方差相同 |
您最近一年使用:0次


