则下列说法正确的是( )
| A.在回归分析中,残差的平方和越大,模型的拟合效果越好; |
| B.在残差图中,残差点比较均匀地落在水平的带状区域内,说明选用的模型比较合适; |
C.若数据 , ,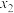 , , , ,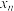 的平均数为1,则 的平均数为1,则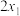 , ,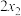 ,, ,,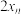 的平均数为2; 的平均数为2; |
D.对分类变量x与y的随机变量 来说,越大,判断“x与y有关系”的把握越大. 来说,越大,判断“x与y有关系”的把握越大. |
更新时间:2022-02-12 16:27:33
|
相似题推荐
多选题
|
较易
(0.85)
名校
【推荐1】下列说法中正确的是( )
| A.用简单随机抽样的方法从含有60个个体的总体中抽取一个容量为6的样本,则个体m被抽到的概率是0.1 |
B.已知一组数据1,2,m,6,7的平均数为4,则这组数据的方差是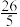 |
| C.数据13,27,24,12,14,30,15,17,19,23的第70百分位数是23 |
D.若样本数据 的标准差为8,则数据 的标准差为8,则数据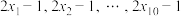 的标准差为32 的标准差为32 |
您最近一年使用:0次
多选题
|
较易
(0.85)
名校
【推荐2】第24届冬季奥林匹克运动会将于2022年2月4日在北京开幕.为了普及冰雪运动,某社区举办了一个冰雪运动知识竞赛,并为所有参与竞赛的居民设置了一等奖、二等奖、三等奖以及参与奖,且奖品的单价分别为:一等奖300元、二等奖200元、三等奖100元、参与奖50元,获奖人数的分配情况如图所示,则以下说法正确的是( )
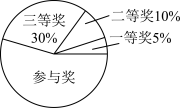
| A.参与奖总费用最高三等奖 |
| B.三等奖的总费用是一等奖总费用的2倍 |
C.购买奖品的费用的平均数为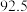 元 元 |
| D.奖品的费用的中位数为50元 |
您最近一年使用:0次

多选题
|
较易
(0.85)
名校
【推荐1】随机变量X和Y的相关系数为r,则下列说法正确的是( )
A.当 时,X和Y具有正线性相关性 时,X和Y具有正线性相关性 | B.随着r值减小,X和Y的相关性也减小 |
C.当 时,X和Y不具有相关性 时,X和Y不具有相关性 | D.当 时,X和Y具有较强的线性相关性 时,X和Y具有较强的线性相关性 |
您最近一年使用:0次
多选题
|
较易
(0.85)
名校
【推荐2】下列说法正确的是( )
A.若样本数据 的方差为4,则数据 的方差为4,则数据 的方差为9 的方差为9 |
B.若随机变量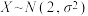 , ,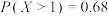 ,则 ,则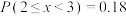 |
C.若线性相关系数 越接近1,则两个变量的线性相关性越弱 越接近1,则两个变量的线性相关性越弱 |
D.若事件A,B满足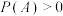 , ,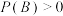 , ,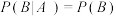 ,则有 ,则有 |
您最近一年使用:0次
多选题
|
较易
(0.85)
【推荐3】下列命题中正确的是( ).
A.对于任意两个事件A与B,如果 ,则事件A与B独立 ,则事件A与B独立 |
B.两组数据,,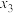 ,..., ,...,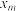 与 与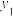 , ,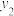 , ,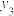 ,..., ,...,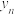 ,设它们的平均值分别为 ,设它们的平均值分别为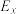 与 与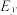 ,将它们合并在一起,则总体的平均值为 ,将它们合并在一起,则总体的平均值为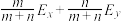 |
C.已知离散型随机变量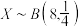 ,则 ,则 |
| D.线性回归模型中,相关系数r的值越大,则这两个变量线性相关性越强 |
您最近一年使用:0次
多选题
|
较易
(0.85)
【推荐1】下列有关说法正确的是( )
A.用决定系数 来刻画回归的效果时,的值越小,说明模型拟合的效果越好 来刻画回归的效果时,的值越小,说明模型拟合的效果越好 |
B.已知回归模型为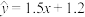 ,则样本 ,则样本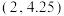 的残差为0.05 的残差为0.05 |
| C.数据2,3,5,6,8,11,13,14的第80百分位数为13 |
D.一组样本数据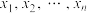 的平均数是3,则 的平均数是3,则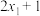 , ,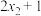 ,, ,,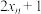 的平均数是7 的平均数是7 |
您最近一年使用:0次
多选题
|
较易
(0.85)
名校
【推荐2】进入21世纪以来,全球二氧化碳排放量增长迅速,自2000年至今,全球二氧化碳排放量增加了约40%,我国作为发展中国家,经济发展仍需要大量的煤炭能源消耗.下图是2016—2020年中国二氧化碳排放量的统计图表(以2016年为第1年).利用图表中数据计算可得,采用某非线性回归模型拟合时,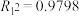 ;采用一元线性回归模型拟合时,线性回归方程为
;采用一元线性回归模型拟合时,线性回归方程为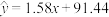 ,
, .则下列说法正确的是( )
.则下列说法正确的是( )
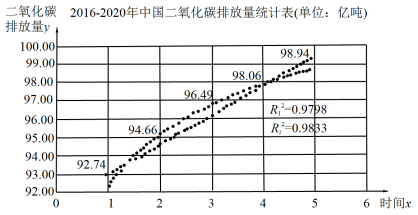
;采用一元线性回归模型拟合时,线性回归方程为,.则下列说法正确的是( )| A.由图表可知,二氧化碳排放量y与时间x正相关 |
| B.由决定系数可以看出,线性回归模型的拟合程度更好 |
| C.利用线性回归方程计算2019年所对应的样本点的残差为-0.30 |
| D.利用线性回归方程预计2025年中国二氧化碳排放量为107.24亿吨 |
您最近一年使用:0次
 一定过样本点中心
一定过样本点中心
多选题
|
较易
(0.85)
【推荐1】下列说法错误 的是( )
A.当样本相关系数 满足 满足 时,成对样本数据的两个分量之间满足一种线性关系 时,成对样本数据的两个分量之间满足一种线性关系 |
| B.残差等于预测值减去观测值 |
| C.决定系数越大,模型拟合效果越差 |
D.在独立性检验中,当 ( ( 为 为 的临界值)时,推断零假设 的临界值)时,推断零假设 不成立 不成立 |
您最近一年使用:0次
多选题
|
较易
(0.85)
解题方法
【推荐2】下列说法正确的有( )
| A.在研究成对数据的相关关系时,相关关系越强,相关系数越接近于1 |
| B.独立性检验是在零假设之下,如果出现一个与相矛盾的小概率事件,就推断不成立,且该推断犯错误的概率不超过这个小概率 |
C.已知一组样本数据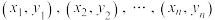 ,根据这组数据的散点图分析 ,根据这组数据的散点图分析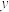 与 与 之间的具有线性相关关系,若求得其线性回归方程为 之间的具有线性相关关系,若求得其线性回归方程为 ,则在样本点 ,则在样本点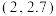 处的残差为 处的残差为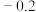 |
D.以模型 去拟合一组数据时,为了求出回归方程,设 去拟合一组数据时,为了求出回归方程,设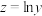 ,将其变换后得到线性方程 ,将其变换后得到线性方程 ,则 ,则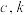 的值分别是 的值分别是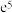 和0. 3 和0. 3 |
您最近一年使用:0次


