名校
解题方法
1 . 将保护区分为面积大小相近的多个区域,用简单随机抽样的方法抽取其中15个区域进行编号,统计抽取到每个区域的某种水源指标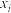 和区域内该植物分布的数量
和区域内该植物分布的数量 (
( ,2,…,15),得到数组
,2,…,15),得到数组 .已知
.已知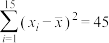 ,
, ,
, .
.
(1)求样本(,2…,15)的相关系数;
(2)假设该植物的寿命为随机变量X(X可取任意正整数).研究人员统计大量数据后发现:对于任意的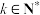 ,寿命为
,寿命为 的样本在寿命超过k的样本里的数量占比与寿命为1的样本在全体样本中的数量占比相同,均等于0.1,这种现象被称为“几何分布的无记忆性”.
的样本在寿命超过k的样本里的数量占比与寿命为1的样本在全体样本中的数量占比相同,均等于0.1,这种现象被称为“几何分布的无记忆性”.
(ⅰ)求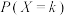 ()的表达式;
()的表达式;
(ⅱ)推导该植物寿命期望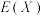 的值.
的值.
附:相关系数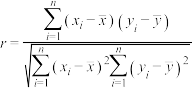 .
.
和区域内该植物分布的数量(,2,…,15),得到数组.已知,,.(1)求样本
(,2…,15)的相关系数;(2)假设该植物的寿命为随机变量X(X可取任意正整数).研究人员统计大量数据后发现:对于任意的
,寿命为的样本在寿命超过k的样本里的数量占比与寿命为1的样本在全体样本中的数量占比相同,均等于0.1,这种现象被称为“几何分布的无记忆性”.(ⅰ)求
()的表达式;(ⅱ)推导该植物寿命期望
的值.附:相关系数
.
您最近半年使用:0次
2024-04-13更新
|
1054次组卷
|
2卷引用:湖南省部分学校2024届高三下学期一起考大联考模拟(二)数学试题
名校
2 . 某校20名学生的数学成绩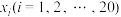 和知识竞赛成绩
和知识竞赛成绩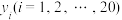 如下表:
如下表:
学生编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
数学成绩 | 100 | 99 | 96 | 93 | 90 | 88 | 85 | 83 | 80 | 77 |
知识竞赛成绩 | 290 | 160 | 220 | 200 | 65 | 70 | 90 | 100 | 60 | 270 |
学生编号 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
数学成绩 | 75 | 74 | 72 | 70 | 68 | 66 | 60 | 50 | 39 | 35 |
知识竞赛成绩 | 45 | 35 | 40 | 50 | 25 | 30 | 20 | 15 | 10 | 5 |
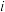
计算可得数学成绩的平均值是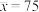 ,知识竞赛成绩的平均值是
,知识竞赛成绩的平均值是 ,并且
,并且 ,
, ,
,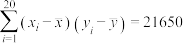 .
.
(1)求这组学生的数学成绩和知识竞赛成绩的样本相关系数(精确到
 ).
).(2)设
 ,变量
,变量 和变量
和变量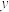 的一组样本数据为
的一组样本数据为 ,其中
,其中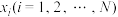 两两不相同,
两两不相同,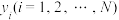 两两不相同.记在
两两不相同.记在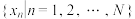 中的排名是第
中的排名是第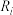 位,在
位,在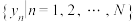 中的排名是第
中的排名是第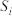 位,
位,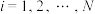 .定义变量和变量的“斯皮尔曼相关系数”(记为
.定义变量和变量的“斯皮尔曼相关系数”(记为 )为变量的排名和变量的排名的样本相关系数.
)为变量的排名和变量的排名的样本相关系数.(i)记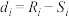 ,.证明:
,.证明: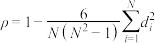 .
.
(ii)用(i)的公式求这组学生的数学成绩和知识竞赛成绩的“斯皮尔曼相关系数”(精确到).
(3)比较(1)和(2)(ii)的计算结果,简述“斯皮尔曼相关系数”在分析线性相关性时的优势.
注:参考公式与参考数据.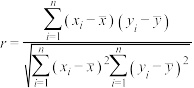 ;
; ;
;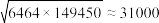 .
.
您最近半年使用:0次
2023-05-19更新
|
988次组卷
|
5卷引用:2023届高三新高考数学原创模拟试题
2023届高三新高考数学原创模拟试题浙江省宁波市奉化区九校联考2022-2023学年高二下学期期末模拟数学试题重庆市江北区第十八中学2023-2024学年高三上学期11月检测(一)数学试题(已下线)第八章 成对数据的统计分析(压轴题专练)-2023-2024学年高二数学单元速记·巧练(人教A版2019选择性必修第三册)(已下线)第9章 统计 章末题型归纳总结-【帮课堂】2023-2024学年高二数学同步学与练(苏教版2019选择性必修第二册)
名校
解题方法
3 . 移动物联网广泛应用于生产制造、公共服务、个人消费等领域.截至2022年底,我国移动物联网连接数达18.45亿户,成为全球主要经济体中首个实现“物超人”的国家.右图是2018-2022年移动物联网连接数W与年份代码t的散点图,其中年份2018-2022对应的t分别为1~5.
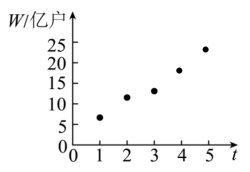
(1)根据散点图推断两个变量是否线性相关.计算样本相关系数(精确到0.01),并推断它们的相关程度;
(2)(i)假设变量x与变量Y的n对观测数据为(x1,y1),(x2,y2),…,(xn,yn),两个变量满足一元线性回归模型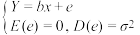 (随机误差
(随机误差 ).请推导:当随机误差平方和Q=
).请推导:当随机误差平方和Q=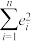 取得最小值时,参数b的最小二乘估计.
取得最小值时,参数b的最小二乘估计.
(ii)令变量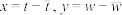 ,则变量x与变量Y满足一元线性回归模型利用(i)中结论求y关于x的经验回归方程,并预测2024年移动物联网连接数.
,则变量x与变量Y满足一元线性回归模型利用(i)中结论求y关于x的经验回归方程,并预测2024年移动物联网连接数.
附:样本相关系数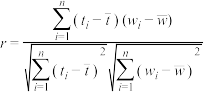 ,
,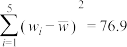 ,
,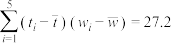 ,
,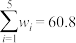 ,
,
(1)根据散点图推断两个变量是否线性相关.计算样本相关系数(精确到0.01),并推断它们的相关程度;
(2)(i)假设变量x与变量Y的n对观测数据为(x1,y1),(x2,y2),…,(xn,yn),两个变量满足一元线性回归模型
(随机误差).请推导:当随机误差平方和Q=取得最小值时,参数b的最小二乘估计.(ii)令变量
,则变量x与变量Y满足一元线性回归模型利用(i)中结论求y关于x的经验回归方程,并预测2024年移动物联网连接数.附:样本相关系数
,,,,
您最近半年使用:0次
2023-03-07更新
|
3581次组卷
|
16卷引用:福建省厦门市2023届高三下学期第二次质量检测数学试题
福建省厦门市2023届高三下学期第二次质量检测数学试题(已下线)9.1.2线性回归方程(2)(已下线)模块三 专题6 概率与统计专题24计数原理与概率与统计(解答题)河北省石家庄第二中学2023届高三下学期5月月考数学试题四川省成都市石室中学2023届高三适应性模拟检测理科数学试题福建省福州市鼓山中学2023届高三下学期3月月考数学试题8.2.2一元线性回归模型参数的最小二乘估计练习(已下线)2024届数学新高考学科基地秘卷(六)(已下线)统 计专题16回归分析(已下线)专题05 成对数据的统计分析压轴题(4)(已下线)第八章 成对数据的统计分析(压轴题专练)-2023-2024学年高二数学单元速记·巧练(人教A版2019选择性必修第三册)(已下线)专题11 统计与概率(分层练)(已下线)第八章 成对数据的统计分析(压轴题专练)-2023-2024学年高二数学单元速记·巧练(沪教版2020选择性必修第二册)(已下线)【一题多变】 相关关系 回归分析
名校
解题方法
4 . 小明在家独自用下表分析高三前5次月考中数学的班级排名y与考试次数x的相关性时,忘记了第二次和第四次月考排名,但小明记得平均排名 ,于是分别用m=6和m=8得到了两条回归直线方程:
,于是分别用m=6和m=8得到了两条回归直线方程: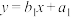 ,
,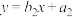 ,对应的相关系数分别为
,对应的相关系数分别为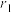 、
、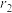 ,排名y对应的方差分别为
,排名y对应的方差分别为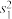 、
、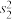 ,则下列结论正确的是( )
,则下列结论正确的是( )
(附: ,
,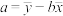 )
)
,于是分别用m=6和m=8得到了两条回归直线方程:,,对应的相关系数分别为、,排名y对应的方差分别为、,则下列结论正确的是( )x | 1 | 2 | 3 | 4 | 5 |
y | 10 | m | 6 | n | 2 |
,)A.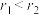 | B. | C. | D.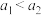 |
您最近半年使用:0次
2023-02-22更新
|
1643次组卷
|
7卷引用:重庆市巴蜀中学2023届高三高考适应性月考(六)数学试题
重庆市巴蜀中学2023届高三高考适应性月考(六)数学试题(已下线)成对数据的统计分析章末测试卷(二)-【帮课堂】2022-2023学年高二数学同步精品讲义(人教A版2019选择性必修第三册)湖北省武汉市第四十九中学2024届高三上学期九月调考模拟数学试题(二)(已下线)第九章 统计与成对数据的统计分析(测试)(已下线)统 计(已下线)专题05 成对数据的统计分析压轴题(4)浙江省舟山市舟山中学2023-2024学年高二下学期4月清明返校测试数学试题
解题方法
5 . 维尼纶纤维的耐热水性能的好坏可以用指标“缩醛化度”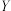 来衡量,这个指标越高,耐热水性能也越好,而甲醛浓度是影响缩醛化度的重要因素,在生产中常用甲醛浓度
来衡量,这个指标越高,耐热水性能也越好,而甲醛浓度是影响缩醛化度的重要因素,在生产中常用甲醛浓度 (单位:
(单位: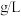 )去控制这一指标,为此必须找出它们之间的关系,现安排一批实验,获得如下数据:
)去控制这一指标,为此必须找出它们之间的关系,现安排一批实验,获得如下数据:
(1)画散点图;
(2)求线性回归方程;
(3)求相关系数
来衡量,这个指标越高,耐热水性能也越好,而甲醛浓度是影响缩醛化度的重要因素,在生产中常用甲醛浓度(单位:)去控制这一指标,为此必须找出它们之间的关系,现安排一批实验,获得如下数据:甲醛浓度 /( | 18 | 20 | 22 | 24 | 26 | 28 | 30 |
缩醛化度 /克分子% | 26.86 | 28.35 | 28.75 | 28.87 | 29.75 | 30.00 | 30.36 |
(2)求线性回归方程;
(3)求相关系数
您最近半年使用:0次
6 . 某统计部门依据《中国统计年鉴——2017》提供的数据,对我国1997-2016年的国内生产总值(GDP)进行统计研究,作出了两张散点图:图1表示1997-2016年我国的国内生产总值(GDP),图2表示2007-2016年我国的国内生产总值(GDP).
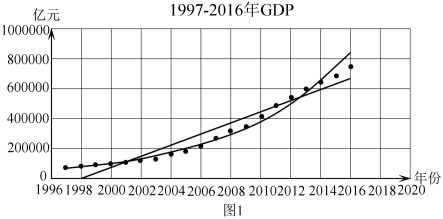
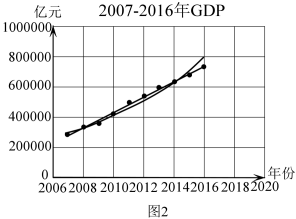
(1)用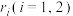 表示第i张图中的年份与GDP的线性相关系数,
表示第i张图中的年份与GDP的线性相关系数, ,依据散点图的特征分别写出
,依据散点图的特征分别写出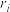 的结果;
的结果;
(2)分别用线性回归模型和指数回归模型对两张散点图进行回归拟合,分别计算出统计数据——相关指数 的数值,部分结果如下表所示:
的数值,部分结果如下表所示:
①将上表中的数据补充完整(结果保留3位小数,直接写在答题卡上);
②若估计2017年的GDP,结合数据说明采用哪张图中的哪种回归模型会更精准一些?若按此回归模型来估计,2020年的GDP能否突破100万亿元?事实上,2020年的GDP刚好突破了100万亿元,估计与事实是否吻合?结合散点图解释说明.
(1)用
表示第i张图中的年份与GDP的线性相关系数,,依据散点图的特征分别写出的结果;(2)分别用线性回归模型和指数回归模型对两张散点图进行回归拟合,分别计算出统计数据——相关指数
的数值,部分结果如下表所示:| 年份 | 1997-2016 | 2007-2016 |
| 线性回归模型 | 0.9306 | |
| 指数回归模型 | 0.9899 | 0.978 |
②若估计2017年的GDP,结合数据说明采用哪张图中的哪种回归模型会更精准一些?若按此回归模型来估计,2020年的GDP能否突破100万亿元?事实上,2020年的GDP刚好突破了100万亿元,估计与事实是否吻合?结合散点图解释说明.
您最近半年使用:0次
2022-01-12更新
|
1148次组卷
|
4卷引用:河北省唐山市2022届高三上学期期末数学试题
河北省唐山市2022届高三上学期期末数学试题(已下线)专题23 回归方程- 2022届高考数学一模试题分类汇编(新高考卷)(已下线)第01讲 线性回归分析-【帮课堂】2021-2022学年高二数学同步精品讲义(苏教版2019选择性必修第二册)河北省沧州市海兴县2023届高三上学期12月调研数学试题


