1 . 下列命题中正确的是( )
| A.在回归分析中,成对样本数据的样本相关系数r的绝对值越大,成对样本数据的线性相关程度越强 |
B.在回归分析中,可用决定系数 的值判断模型的拟合效果,越大,模型的拟合效果越好 的值判断模型的拟合效果,越大,模型的拟合效果越好 |
| C.比较两个模型的拟合效果,可以比较残差平方和的大小,残差平方和越小的模型拟合效果越差 |
D.对分类变量X与Y,统计量 的值越大,则判断“X与Y有关系”的把握程度越大 的值越大,则判断“X与Y有关系”的把握程度越大 |
您最近一年使用:0次
2022-07-15更新
|
998次组卷
|
5卷引用:山东省济宁市2021-2022学年高二下学期期末数学试题
山东省济宁市2021-2022学年高二下学期期末数学试题(已下线)第03讲 成对数据的统计分析 (精讲)(已下线)8.3.2 独立性检验(分层作业)-【上好课】2022-2023学年高二数学同步备课系列(人教A版2019选修第三册)黑龙江省宾县第二中学2023-2024学年高三上学期期初学业质量检测数学试题(已下线)重难专攻(十三) 概率与统计的综合问题 A卷素养养成卷
名校
解题方法
2 . 下列说法正确的是( )
| A.将一组数据中的每一个数据都加上同一个常数后,方差不变 |
B.设具有线性相关关系的两个变量x,y的相关系数为r,则 越接近于0,x和y之间的线性相关程度越强 越接近于0,x和y之间的线性相关程度越强 |
C.在一个 列联表中,由计算得 列联表中,由计算得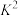 的值,则的值越小,判断两个变量有关的把握越大 的值,则的值越小,判断两个变量有关的把握越大 |
D.若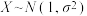 , , ,则 ,则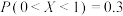 |
您最近一年使用:0次
2022-03-05更新
|
1104次组卷
|
4卷引用:山东省济宁市2022届高三一模数学(3月)试题
山东省济宁市2022届高三一模数学(3月)试题(已下线)临考押题卷05-2022年高考数学临考押题卷(新高考卷)江苏省盐城市阜宁县东沟中学2022届高三下学期第一次综合训练数学试题江苏省盐城市阜宁县东沟中学2022-2023学年高三上学期第一次综合训练数学试题
名校
3 . 下列说法:
①对于独立性检验, 的值越大,说明两事件相关程度越大;
的值越大,说明两事件相关程度越大;
②以模型 去拟合一组数据时,为了求出回归方程,设
去拟合一组数据时,为了求出回归方程,设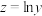 ,将其变换后得到线性方程
,将其变换后得到线性方程 ,则
,则 ,
,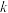 的值分别是
的值分别是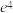 和0.3;
和0.3;
③已知随机变量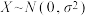 ,若
,若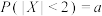 ,则
,则 (
( )的值为
)的值为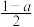 ;
;
④通过回归直线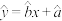 及回归系数
及回归系数 ,可以精确反映变量的取值和变化趋势.
,可以精确反映变量的取值和变化趋势.
其中错误的选项是( )
①对于独立性检验,
的值越大,说明两事件相关程度越大;②以模型
去拟合一组数据时,为了求出回归方程,设,将其变换后得到线性方程,则,的值分别是和0.3;③已知随机变量
,若,则()的值为;④通过回归直线
及回归系数,可以精确反映变量的取值和变化趋势.其中错误的选项是( )
| A.① | B.② | C.③ | D.④ |
您最近一年使用:0次
名校
4 . 下列命题中正确的命题是( )
| A.标准差越小,则反映样本数据的离散程度越大 |
B.在回归直线方程 中,当解释变量 中,当解释变量 每增加1个单位时,则预报变量 每增加1个单位时,则预报变量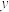 减少0.4个单位 减少0.4个单位 |
C.对分类变量 与 与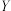 来说,它们的随机变量的观测值越小,“与有关系”的把握程度越大 来说,它们的随机变量的观测值越小,“与有关系”的把握程度越大 |
| D.在回归分析模型中,残差平方和越小,说明模型的拟合效果越好 |
您最近一年使用:0次
名校
5 . 下列说法正确的是
A.回归直线至少经过其样本数据 中的一个点 中的一个点 |
| B.从独立性检验可知有99%的把握认为吃地沟油与患胃肠癌有关系时,我们就说如果某人吃地沟油,那么他有99%可能患胃肠癌 |
| C.在残差图中,残差点分布的带状区域的宽度越狭窄,其模型拟合的精度越高 |
| D.将一组数据的每一个数据都加上或减去同一个常数后,其方差也要加上或减去这个常数 |
您最近一年使用:0次
2020-03-22更新
|
533次组卷
|
7卷引用:2020届山东省济宁市高三3月线上数学试题
2020届山东省济宁市高三3月线上数学试题2020届山东省曲阜市第一中学高三下学期3月线上自我检测数学试题福建省莆田第二十四中学2019-2020学年高二下学期期中测试数学(文)试题甘肃省张掖市高台县第一中学2019-2020学年高二下学期期中考试数学(文)试题(已下线)第 10 篇——概率统计-新高考山东专题汇编(已下线)专题9.3 统计与统计案例-备战2021年高考数学精选考点专项突破题集(新高考地区)山东省淄博市临淄中学2020-2021学年高三上学期期中数学试题
6 . 甲、乙两企业生产同一种型号零件,按规定该型号零件的质量指标值落在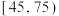 内为优质品.从两个企业生产的零件中各随机抽出了500件,测量这些零件的质量指标值,得结果如下表:
内为优质品.从两个企业生产的零件中各随机抽出了500件,测量这些零件的质量指标值,得结果如下表:
甲企业:

乙企业:

(1)已知甲企业的500件零件质量指标值的样本方差 ,该企业生产的零件质量指标值服从正态分布
,该企业生产的零件质量指标值服从正态分布 ,其中
,其中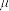 近似为质量指标值的样本平均数
近似为质量指标值的样本平均数 (注:求时,同一组数据用该区间的中点值作代表),
(注:求时,同一组数据用该区间的中点值作代表), 近似为样本方差
近似为样本方差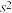 ,试根据该企业的抽样数据,估计所生产的零件中,质量指标值不低于71.92的产品的概率.(精确到0.001)
,试根据该企业的抽样数据,估计所生产的零件中,质量指标值不低于71.92的产品的概率.(精确到0.001)
(2)由以上统计数据完成下面列联表,并问能否在犯错误的概率不超过0.01的前提下,认为“两个分厂生产的零件的质量有差异”.

附注:
参考数据: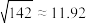 ,
,
参考公式: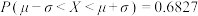 ,
,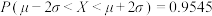 ,
,
 .
.

内为优质品.从两个企业生产的零件中各随机抽出了500件,测量这些零件的质量指标值,得结果如下表:甲企业:
乙企业:
(1)已知甲企业的500件零件质量指标值的样本方差
,该企业生产的零件质量指标值服从正态分布,其中近似为质量指标值的样本平均数(注:求时,同一组数据用该区间的中点值作代表),近似为样本方差,试根据该企业的抽样数据,估计所生产的零件中,质量指标值不低于71.92的产品的概率.(精确到0.001)(2)由以上统计数据完成下面
列联表,并问能否在犯错误的概率不超过0.01的前提下,认为“两个分厂生产的零件的质量有差异”.附注:
参考数据:
,参考公式:
,,.
| 0.50 | 0.40 | 0.25 | 0.15 | 0.10 | 0.05 | 0.025 | 0.010 | 0.005 | 0.001 |
| 0.455 | 0.708 | 1.323 | 2.072 | 2.706 | 3.841 | 5.024 | 6.635 | 7.879 | 10.828 |


您最近一年使用:0次
2017-08-18更新
|
303次组卷
|
2卷引用:山东省济宁市2016-2017学年高二下学期期末考试理数试题
10-11高二下·山东济宁·期末
7 . 分类变量X和Y的列表如下,则下列说法判断正确的是________ .(填序号)
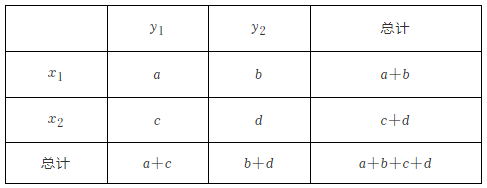
① 越小,说明X与Y的关系越弱;②越大,说明X与Y的关系越强;
越小,说明X与Y的关系越弱;②越大,说明X与Y的关系越强;
③ 越大,说明X与Y的关系越强;④越接近于0,说明X与Y的关系越强.
越大,说明X与Y的关系越强;④越接近于0,说明X与Y的关系越强.
①
越小,说明X与Y的关系越弱;②越大,说明X与Y的关系越强;③
越大,说明X与Y的关系越强;④越接近于0,说明X与Y的关系越强.
您最近一年使用:0次


