1 . 某兴趣小组研究光照时长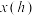 和向日葵种子发芽数量y(颗)之间的关系,采集5组数据,作如图所示的散点图.若去掉
和向日葵种子发芽数量y(颗)之间的关系,采集5组数据,作如图所示的散点图.若去掉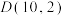 后,下列说法正确的是( )
后,下列说法正确的是( )
和向日葵种子发芽数量y(颗)之间的关系,采集5组数据,作如图所示的散点图.若去掉后,下列说法正确的是( )
| A.相关系数r的绝对值变小 | B.相关指数 变小 变小 |
| C.残差平方和变大 | D.解释变量x与响应变量y的相关性变强 |
您最近一年使用:0次
2 . 为考查某种药物预防疾病的效果,进行动物试验,得到以下数据:
常用小概率值和相应临界值:
由以上数据,计算得到 ,根据临界值表,以下说法正确的是( )
,根据临界值表,以下说法正确的是( )
药物 | 疾病 | |
未患病 | 患病 | |
未服用 | 75 | 65 |
服用 | 105 | 55 |
|
|
|
|
|
|
|
|
|
|
|
|




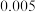
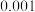





 ,根据临界值表,以下说法正确的是( )
,根据临界值表,以下说法正确的是( )A.根据小概率值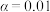 的独立性检验,认为服用药物与患病没有关联. 的独立性检验,认为服用药物与患病没有关联. |
B.根据小概率值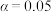 的独立性检验,认为服用药物与患病没有关联. 的独立性检验,认为服用药物与患病没有关联. |
| C.根据小概率值的独立性检验,推断服用药物与患病有关联,此推断犯错误的概率不超过0.01. |
| D.根据小概率值的独立性检验,推断服用药物与患病有关联,此推断犯错误的概率不超过0.05. |
您最近一年使用:0次
3 . 下列说法错误 的是( )
A. 是用来判断两个分类变量是否相关的随机变量,当的值很小时可以推断两个变量相关性比较小 是用来判断两个分类变量是否相关的随机变量,当的值很小时可以推断两个变量相关性比较小 |
| B.在残差图中,残差图的横坐标可以是编号、解释变量和预报变量 |
| C.残差点分布的带状区域的宽度越窄,残差平方和越大 |
D.已知一组样本点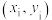 ,其中 ,其中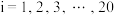 ,根据最小二乘法求得的回归直线方程是 ,根据最小二乘法求得的回归直线方程是 ,若所有样本点都在回归直线上,则变量间相关系数为1 ,若所有样本点都在回归直线上,则变量间相关系数为1 |
您最近一年使用:0次
解题方法
4 . 某市学生校车由“通达”和“运达”两家公司运营,为了解这两家公司长途客车的运行情况,随机调查了两家公司200天校车早上是否准时到校情况,并统计了如下列联表:
(1)根据上表,分别估计“通达”和“运达”两家公司早上准时到校的概率;
(2)能否有95%的把握认为校车早上是否准时到校与校车所属的公司有关?
附: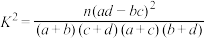 ,
,
准时到校天数 | 未准时到校天数 | |
通达 | 96 | 8 |
运达 | 84 | 12 |
(2)能否有95%的把握认为校车早上是否准时到校与校车所属的公司有关?
附:
,
| 0.100 | 0.050 | 0.010 |
k | 2.706 | 3.841 | 6.635 |

您最近一年使用:0次
5 . 下列说法中正确是( )
A.相关系数 越大,则两变量的相关性就越强 越大,则两变量的相关性就越强 |
| B.回归方程不一定过样本中心点 |
C.对于经验回归方程 ,当变量 ,当变量 增加1个单位时, 增加1个单位时,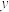 平均增加3个单位 平均增加3个单位 |
D.对于经验回归方程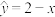 ,变量与变量负相关 ,变量与变量负相关 |
您最近一年使用:0次
6 . 下列说法错误 的是( )
| A.独立性检验的结果一定正确 |
B.用卡方检验法判断“是否有把握认为吸烟与患肺癌有关”时,其零假设为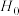 :吸烟与患肺癌之间无关联 :吸烟与患肺癌之间无关联 |
| C.在线性回归分析中,相关系数的值越大,说明回归方程拟合的效果越好 |
| D.根据一元线性回归模型中对随机误差的假定,残差的均值为0 |
您最近一年使用:0次
7 . 下列说法正确的是( )
| A.两个随机变量的线性相关性越强,相关系数的绝对值越接近于1 |
B.运用最小二乘法求得的回归直线一定经过样本中心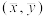 |
C.在一个 列联表中,计算得到的值,若的值越小,则可以判断两个变量有关的概率越大 列联表中,计算得到的值,若的值越小,则可以判断两个变量有关的概率越大 |
D.利用独立性检验推断“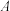 与 与 是否有关”,根据数据算得 是否有关”,根据数据算得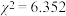 ,已知 ,已知 , ,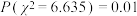 ,则有超过 ,则有超过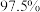 的把握认为与无关 的把握认为与无关 |
您最近一年使用:0次
8 . 下列说法正确的是( )
| A.与中位数相比,平均数反映出样本数据中的更多信息,对样本中的极端值更加敏感 |
B.数据 的第 的第 百分位数为 百分位数为 |
C.已知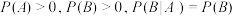 ,则 ,则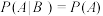 |
D.当样本相关系数的绝对值越接近 时,成对样本数据的线性相关程度越强 时,成对样本数据的线性相关程度越强 |
您最近一年使用:0次
9 . 数据与有较强的线性相关关系,通过计算得到关于的线性回归方程为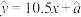 ,经过分析、计算得
,经过分析、计算得 ,则样本点
,则样本点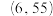 的残差为( )
的残差为( )
A.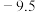 | B.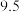 | C. | D.64.5 |
您最近一年使用:0次
10 . 近几年,电商的蓬勃发展带动了快递行业的迅速增长.为了获得更大的利润,某快递公司在 城市的网点对“一天中收发一件块递的平均成本
城市的网点对“一天中收发一件块递的平均成本 (单位:元)与当天揽收的快递件数
(单位:元)与当天揽收的快递件数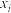 (单位:千件)之间的关系”进行调查研究,得到相关数据如下表:
(单位:千件)之间的关系”进行调查研究,得到相关数据如下表:
根据以上数据,技术人员分别根据甲、乙两种不同的回归模型,得到两个经验回归方程:方程甲: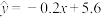 ,方程乙:
,方程乙: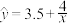 .
.
(1)为了评价两种模型的拟合效果,完成以下问题:
①根据上表数据和相应回归方程,将以下表格填写完整(结果保留一位小数):
( 备注: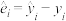 称为相应于点
称为相应于点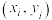 的随机误差)
的随机误差)
②分别计算模型甲与模型乙的随机误差平方和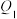 ,
, 并依此判断哪个模型的拟合效果更好.
并依此判断哪个模型的拟合效果更好.
(2)已知该快递网点每天能揽收的快递件数(单位:千件)与揽收一件快递的平均价格 (单位:元)之间的关系是
(单位:元)之间的关系是 ,根据(1)中拟合效果较好的模型建立的回归方程解决以下问题:
,根据(1)中拟合效果较好的模型建立的回归方程解决以下问题:
①若一天揽收快递6千件,则当天总利润的预报值是多少?
②为使每天获得的总利润最高,该快递网点应该将揽收一件快递的平均价格定为多少?(备注:利润=价格-成本)
城市的网点对“一天中收发一件块递的平均成本(单位:元)与当天揽收的快递件数(单位:千件)之间的关系”进行调查研究,得到相关数据如下表:每天揽收快递件数 | 2 | 3 | 4 | 5 | 8 |
每件快递的平均成本 | 5.6 | 4.8 | 4.4 | 4.3 | 4.1 |
,方程乙:.(1)为了评价两种模型的拟合效果,完成以下问题:
①根据上表数据和相应回归方程,将以下表格填写完整(结果保留一位小数):
| 每天揽收快递件数xi/千件 | 2 | 3 | 4 | 5 | 8 | |
| 每件快递的平均成本yi/元 | 5.6 | 4.8 | 4.4 | 4.3 | 4.1 | |
| 模型甲 | 预报值 | 5.2 | 5 | 4.8 | ||
随机误差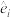 | -0.4 | 0.2 | 0.4 | |||
| 模型乙 | 预报值 | 5.5 | 4.8 | 4.5 | ||
| 随机误差 | -0.1 | 0 | 0.1 | |||
称为相应于点的随机误差)②分别计算模型甲与模型乙的随机误差平方和
,并依此判断哪个模型的拟合效果更好.(2)已知该快递网点每天能揽收的快递件数
(单位:千件)与揽收一件快递的平均价格(单位:元)之间的关系是,根据(1)中拟合效果较好的模型建立的回归方程解决以下问题:①若一天揽收快递6千件,则当天总利润的预报值是多少?
②为使每天获得的总利润最高,该快递网点应该将揽收一件快递的平均价格定为多少?(备注:利润=价格-成本)
您最近一年使用:0次


