名校
1 . 混凝土的抗压强度x较容易测定,而抗剪强度y不易测定,工程中希望建立一种能由x推算y的经验公式,下表列出了现有的9对数据,分别为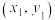 ,
,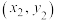 ,…,
,…, .
.
x | 141 | 152 | 168 | 182 | 195 | 204 | 223 | 254 | 277 |
y | 23.1 | 24.2 | 27.2 | 27.8 | 28.7 | 31.4 | 32.5 | 34.8 | 36.2 |
以成对数据的抗压强度x为横坐标,抗剪强度y为纵坐标作出散点图,如图所示.
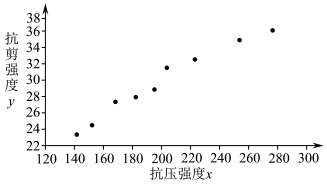
(1)从上表中任选2个成对数据,求该样本量为2的样本相关系数r.结合r值分析,由简单随机抽样得到的成对样本数据的样本相关系数是否一定能确切地反映变量之间的线性相关关系?
(2)根据散点图,我们选择两种不同的函数模型作为回归曲线,根据一元线性回归模型及最小二乘法,得到经验回归方程分别为:①
 ,②
,② .经验回归方程①和②的残差计算公式分别为
.经验回归方程①和②的残差计算公式分别为 ,
,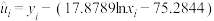 ,
,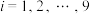 .
.(ⅰ)求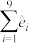 ;
;
(ⅱ)经计算得经验回归方程①和②的残差平方和分别为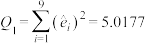 ,
,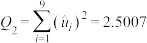 ,经验回归方程①的决定系数
,经验回归方程①的决定系数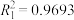 ,求经验回归方程②的决定系数
,求经验回归方程②的决定系数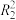 .
.
附:相关系数 ,决定系数
,决定系数 ,
, .
.
您最近半年使用:0次
解题方法
2 . 当前,新一轮科技革命和产业变革蓬勃兴起,以区块链为代表的新一代信息技术迅猛发展,现收集某地近6年区块链企业总数量相关数据,如下表:
年份 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
编号 | 1 | 2 | 3 | 4 | 5 | 6 |
企业总数量 | 50 | 78 | 124 | 121 | 137 | 352 |
(1)若用模型
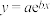 拟合
拟合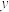 与
与 的关系,根据提供的数据,求出与的经验回归方程;
的关系,根据提供的数据,求出与的经验回归方程;(2)为了促进公司间的合作与发展,区块链联合总部决定进行一次信息化技术比赛,邀请甲、乙、丙三家区块链公司参赛.比赛规则如下:①每场比赛有两个公司参加,并决出胜负;②每场比赛获胜的公司与未参加此场比赛的公司进行下一场的比赛;③在比赛中,若有一个公司首先获胜两场,则本次比赛结束,该公司获得此次信息化比赛的“优胜公司”.已知在每场比赛中,甲胜乙的概率为
 ,甲胜丙的概率为
,甲胜丙的概率为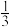 ,乙胜丙的概率为
,乙胜丙的概率为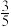 ,若首场由甲乙比赛,求甲公司获得“优胜公司”的概率.
,若首场由甲乙比赛,求甲公司获得“优胜公司”的概率.参考数据: ,其中,
,其中,
参考公式:对于一组数据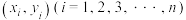 ,其经验回归直线
,其经验回归直线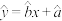 的斜率和截距的最小二乘估计分别为
的斜率和截距的最小二乘估计分别为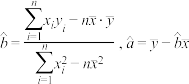
您最近半年使用:0次
3 . 某专营店统计了最近 天到该店购物的人数
天到该店购物的人数 和时间第
和时间第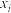 天之间的数据,列表如下:
天之间的数据,列表如下:
(1)由表中给出的数据,判断是否可用线性回归模型拟合人数与时间之间的关系?(若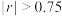 ,则认为线性相关程度高,可用线性回归模型拟合;否则,不可用线性回归模型拟合.计算
,则认为线性相关程度高,可用线性回归模型拟合;否则,不可用线性回归模型拟合.计算 时精确到
时精确到 )
)
(2)该专营店为了吸引顾客,推出两种促销方案:方案一,购物金额每满 元可减
元可减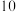 元;方案二,购物金额超过
元;方案二,购物金额超过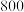 元可抽奖三次,每次中奖的概率均为,且每次抽奖互不影响,中奖一次打
元可抽奖三次,每次中奖的概率均为,且每次抽奖互不影响,中奖一次打 折,中奖两次打
折,中奖两次打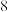 折,中奖三次打
折,中奖三次打 折.某顾客计划在此专营店购买一件价值
折.某顾客计划在此专营店购买一件价值 元的商品,请从实际付款金额的数学期望的角度分析,选哪种方案更优惠?
元的商品,请从实际付款金额的数学期望的角度分析,选哪种方案更优惠?
参考数据: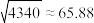 .附:相关系数
.附:相关系数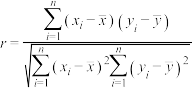 .
.
天到该店购物的人数和时间第天之间的数据,列表如下:
|
|
|
|
|
|
|
|
|
|
|
|







 与时间之间的关系?(若,则认为线性相关程度高,可用线性回归模型拟合;否则,不可用线性回归模型拟合.计算时精确到)
与时间之间的关系?(若,则认为线性相关程度高,可用线性回归模型拟合;否则,不可用线性回归模型拟合.计算时精确到)(2)该专营店为了吸引顾客,推出两种促销方案:方案一,购物金额每满
元可减元;方案二,购物金额超过元可抽奖三次,每次中奖的概率均为,且每次抽奖互不影响,中奖一次打折,中奖两次打折,中奖三次打折.某顾客计划在此专营店购买一件价值元的商品,请从实际付款金额的数学期望的角度分析,选哪种方案更优惠?参考数据:
.附:相关系数.
您最近半年使用:0次
2023-11-07更新
|
952次组卷
|
10卷引用:重庆市九龙坡区育才中学校2024届高三上学期第三次联考复习数学试题
重庆市九龙坡区育才中学校2024届高三上学期第三次联考复习数学试题广东省广州市荔湾区2024届高三上学期十月月考数学试题(已下线)第十章 重难专攻(十三) 概率与统计的综合问题(讲)(已下线)第三节 成对数据的统计分析(第一课时) B卷素养养成卷 一轮复习点点通黑龙江省大兴安岭实验中学(东校区)2024届高三上学期11月月考数学试题8.1.2样本相关系数练习(已下线)8.1 成对数据的统计相关性(分层练习,5大题型)-2023-2024学年高二数学同步精品课堂(人教A版2019选择性必修第三册)(已下线)第01讲 8.1 成对数据的统计相关性(知识清单+5类热点题型精讲+强化分层精练)-【帮课堂】2023-2024学年高二数学同步学与练(人教A版2019选择性必修第三册)(已下线)8.1.1变量的相关关系+8.1.2样本相关系数 第三练 能力提升拔高(已下线)8.1 成对数据的统计相关性——课后作业(提升版)
名校
4 . 某校20名学生的数学成绩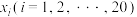 和知识竞赛成绩
和知识竞赛成绩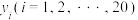 如下表:
如下表:
计算可得数学成绩的平均值是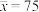 ,知识竞赛成绩的平均值是
,知识竞赛成绩的平均值是 ,并且
,并且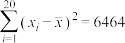 ,
,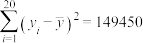 ,
,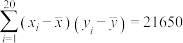 .
.
(1)求这组学生的数学成绩和知识竞赛成绩的样本相关系数(精确到0.01);
(2)设 ,变量和变量的一组样本数据为
,变量和变量的一组样本数据为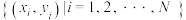 ,其中
,其中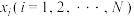 两两不相同,
两两不相同,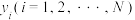 两两不相同.记在
两两不相同.记在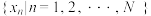 中的排名是第
中的排名是第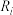 位,在
位,在 中的排名是第
中的排名是第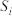 位,
位, .定义变量和变量的“斯皮尔曼相关系数”(记为
.定义变量和变量的“斯皮尔曼相关系数”(记为 )为变量的排名和变量的排名的样本相关系数.
)为变量的排名和变量的排名的样本相关系数.
(i)记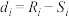 ,.证明:
,.证明: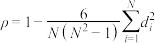 ;
;
(ii)用(i)的公式求得这组学生的数学成绩和知识竞赛成绩的“斯皮尔曼相关系数”约为0.91,简述“斯皮尔曼相关系数”在分析线性相关性时的优势.
注:参考公式与参考数据.
; ;
;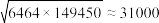 .
.
和知识竞赛成绩如下表:| 学生编号i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数学成绩 | 100 | 99 | 96 | 93 | 90 | 88 | 85 | 83 | 80 | 77 |
| 知识竞赛成绩 | 290 | 160 | 220 | 200 | 65 | 70 | 90 | 100 | 60 | 270 |
| 学生编号i | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 数学成绩 | 75 | 74 | 72 | 70 | 68 | 66 | 60 | 50 | 39 | 35 |
| 知识竞赛成绩 | 45 | 35 | 40 | 50 | 25 | 30 | 20 | 15 | 10 | 5 |
,知识竞赛成绩的平均值是,并且,,.(1)求这组学生的数学成绩和知识竞赛成绩的样本相关系数(精确到0.01);
(2)设
,变量和变量的一组样本数据为,其中两两不相同,两两不相同.记在中的排名是第位,在中的排名是第位,.定义变量和变量的“斯皮尔曼相关系数”(记为)为变量的排名和变量的排名的样本相关系数.(i)记
,.证明:;(ii)用(i)的公式求得这组学生的数学成绩和知识竞赛成绩的“斯皮尔曼相关系数”约为0.91,简述“斯皮尔曼相关系数”在分析线性相关性时的优势.
注:参考公式与参考数据.
;;.
您最近半年使用:0次
2023-11-01更新
|
1188次组卷
|
8卷引用:重庆市北碚区西南大学附中2024届高三上学期11月模拟测试数学试题
重庆市北碚区西南大学附中2024届高三上学期11月模拟测试数学试题山西省朔州市平鲁区李林中学2024届高三上学期开学摸底数学试题(已下线)第十章 综合测试B(提升卷)(已下线)第三节 成对数据的统计分析(第一课时)一轮复习点点通(已下线)第八章 成对数据的统计分析(压轴题专练)-2023-2024学年高二数学单元速记·巧练(人教A版2019选择性必修第三册)(已下线)专题22 新高考新题型第19题新定义压轴解答题归纳(9大核心考点)(讲义)(已下线)第八章 成对数据的统计分析(压轴题专练)-2023-2024学年高二数学单元速记·巧练(沪教版2020选择性必修第二册)(已下线)第八章 成对数据的统计分析(单元重点综合测试)-2023-2024学年高二数学单元速记·巧练(沪教版2020选择性必修第二册)
名校
解题方法
5 . 近年来我国新能源汽车产业迅速发展,下表是某地区新能源乘用车的年销售量与年份的统计表:
某机构调查了该地区位购车车主的性别与购车种类情况,得到的部分数据如下表所示:
(1)求新能源乘用车的销量关于年份的线性相关系数,并判断与之间的线性相关关系的强弱;(若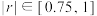 ,相关性较强;若
,相关性较强;若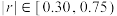 ,相关性一般;若
,相关性一般;若 ,相关性较弱)
,相关性较弱)
(2)请将上述 列联表补充完整,根据小概率值
列联表补充完整,根据小概率值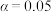 的独立性检验,分析购车车主购置新能源乘用车与性别是否有关系?
的独立性检验,分析购车车主购置新能源乘用车与性别是否有关系?
①参考公式:相关系数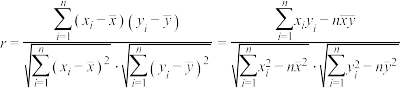 ;
;
②参考数据: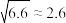 ;
;
③卡方临界值表:
其中 ,
, .
.
年份 |
|
|
|
|
|
销量 |
|
|
|
|
|





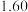
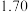
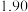
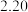
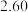 位购车车主的性别与购车种类情况,得到的部分数据如下表所示:
位购车车主的性别与购车种类情况,得到的部分数据如下表所示:购置传统燃油车 | 购置新能源车 | 总计 | |
男性车主 |
|
| |
女性车主 |
| ||
总计 |
|
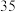

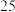 关于年份的线性相关系数,并判断与之间的线性相关关系的强弱;(若,相关性较强;若,相关性一般;若,相关性较弱)
关于年份的线性相关系数,并判断与之间的线性相关关系的强弱;(若,相关性较强;若,相关性一般;若,相关性较弱)(2)请将上述
列联表补充完整,根据小概率值的独立性检验,分析购车车主购置新能源乘用车与性别是否有关系?①参考公式:相关系数
;②参考数据:
;③卡方临界值表:
| 0.10 | 0.05 | 0.010 | 0.005 | 0.001 |
| 2.706 | 3.841 | 6.635 | 7.879 | 10.828 |

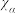 ,.
,.
您最近半年使用:0次
2023-09-30更新
|
719次组卷
|
2卷引用:重庆实验外国语学校2024届高三上学期10月月考数学试题
名校
6 . 已知变量,之间的经验回归方程为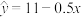 ,且变量,的数据如图所示,则下列说法正确的是( )
,且变量,的数据如图所示,则下列说法正确的是( )
,之间的经验回归方程为,且变量,的数据如图所示,则下列说法正确的是( )
| 2 | 3 | 5 | 9 | 11 |
| 12 | 10 | 7 | 3 |
A.该回归直线必过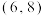 |
| B.变量,之间呈正相关关系 |
C.当 时,变量的值一定等于 时,变量的值一定等于 |
D.相应于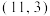 的残差估计值为 的残差估计值为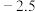 |
您最近半年使用:0次
2023-09-19更新
|
904次组卷
|
4卷引用:重庆市江北区第十八中学2023-2024学年高三上学期11月检测(一)数学试题
7 . 为研究女儿身高与母亲身高的关系,现经过随机抽样获得成对样本数据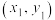 ,
,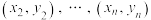 ,下列说法正确的是( )
,下列说法正确的是( )
与母亲身高的关系,现经过随机抽样获得成对样本数据,,下列说法正确的是( )| A.落在回归直线上的样本点越多,回归直线方程的拟合效果越好 |
B.样本相关系数 越大,变量 越大,变量 线性相关程度越强 线性相关程度越强 |
C.决定系数 越小,残差平方和越大,模型的拟合效果越好 越小,残差平方和越大,模型的拟合效果越好 |
| D.决定系数越大,残差平方和越小,模型的拟合效果越好 |
您最近半年使用:0次
2023-09-03更新
|
493次组卷
|
6卷引用:重庆市七校2024届高三上学期开学考试数学试题
重庆市七校2024届高三上学期开学考试数学试题(已下线)第三节 成对数据的统计分析(第一课时)一轮复习点点通(已下线)考点巩固卷23 统计与统计案例(十大考点)(已下线)8.1.2 样本相关系数 (导学案)-【上好课】高二数学同步备课系列(人教A版2019选择性必修第三册)(已下线)8.2 一元线性回归模型及其应用(分层练习,7大题型)-2023-2024学年高二数学同步精品课堂(人教A版2019选择性必修第三册)(已下线)第05讲 第八章 成对数据的统计分析 章末重点题型大总结-【帮课堂】2023-2024学年高二数学同步学与练(人教A版2019选择性必修第三册)
8 . 两个具有相关关系的变量x,y的一组数据为, ,求得样本中心点为
,求得样本中心点为 ,回归直线方程为,决定系数为;若将数据调整为
,回归直线方程为,决定系数为;若将数据调整为 ,
,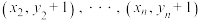 ,求得新的样本中心点为
,求得新的样本中心点为 ,回归直线方程为
,回归直线方程为 ,决定系数为
,决定系数为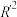 ,则以下说法正确的有( )
,则以下说法正确的有( )
附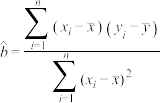 ,
, ,
,
,,求得样本中心点为,回归直线方程为,决定系数为;若将数据调整为,,求得新的样本中心点为,回归直线方程为,决定系数为,则以下说法正确的有( )附
,,A. | B. |
C. | D. |
您最近半年使用:0次
名校
9 . 在正常生产条件下,根据经验,可以认为化肥的有效利用率近似服从正态分布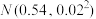 ,而化肥施肥量因农作物的种类不同每亩也存在差异.
,而化肥施肥量因农作物的种类不同每亩也存在差异.
(1)假设生产条件正常,记 表示化肥的有效利用率,求
表示化肥的有效利用率,求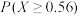 ;
;
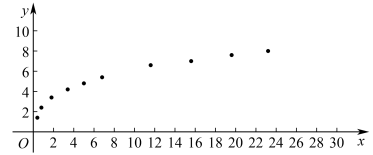
(2)课题组为研究每亩化肥施用量与某农作物亩产量之间的关系,收集了10组数据,并对这些数据作了初步处理,得到了如图所示的散点图及一些统计量的值.其中每亩化肥施用量为(单位:公斤),粮食亩产量为(单位:百公斤)
参考数据:
 ,
,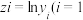 ,2,
,2, ,
, .
.
(i)根据散点图判断, 与
与 ,哪一个适宜作为该农作物亩产量关于每亩化肥施用量的回归方程(给出判断即可,不必说明理由);
,哪一个适宜作为该农作物亩产量关于每亩化肥施用量的回归方程(给出判断即可,不必说明理由);
(ii)根据(i)的判断结果及表中数据,建立关于的回归方程;并预测每亩化肥施用量为27公斤时,粮食亩产量的值.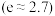
附:①对于一组数据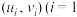 ,2,3,,
,2,3,, ,其回归直线
,其回归直线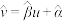 的斜率和截距的最小二乘估计分别为
的斜率和截距的最小二乘估计分别为 ,
,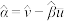 ;
;
②若随机变量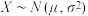 ,则
,则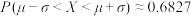 ,
,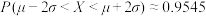 .
.
,而化肥施肥量因农作物的种类不同每亩也存在差异.(1)假设生产条件正常,记
表示化肥的有效利用率,求;(2)课题组为研究每亩化肥施用量与某农作物亩产量之间的关系,收集了10组数据,并对这些数据作了初步处理,得到了如图所示的散点图及一些统计量的值.其中每亩化肥施用量为
(单位:公斤),粮食亩产量为(单位:百公斤) 参考数据:
|
|
|
|
|
|
|
|
650 | 91.5 | 52.5 | 1478.6 | 30.5 | 15 | 15 | 46.5 |
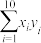

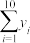
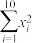
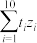
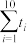
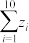
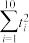 ,,2,,.
,,2,,.(i)根据散点图判断,
与,哪一个适宜作为该农作物亩产量关于每亩化肥施用量的回归方程(给出判断即可,不必说明理由);(ii)根据(i)的判断结果及表中数据,建立
关于的回归方程;并预测每亩化肥施用量为27公斤时,粮食亩产量的值.附:①对于一组数据
,2,3,,,其回归直线的斜率和截距的最小二乘估计分别为,;②若随机变量
,则,.
您最近半年使用:0次
2023-08-18更新
|
932次组卷
|
6卷引用:重庆市第八中学校2023届高三下学期适应性月考(八)数学试题
重庆市第八中学校2023届高三下学期适应性月考(八)数学试题(已下线)第三节 成对数据的统计分析(第一课时)(核心考点集训)一轮复习点点通(已下线)考点巩固卷23 统计与统计案例(十大考点)(已下线)第02讲 成对数据的统计分析(五大题型)(讲义)(已下线)模块一 专题3 统计讲2(已下线)第04讲 拓展一:数学建模 建立统计模型进行预测(非线性回归模型)-【帮课堂】2023-2024学年高二数学同步学与练(人教A版2019选择性必修第三册)
名校
解题方法
10 . 下列说法正确的是( )
A.若样本数据 , ,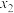 ,…, ,…,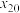 的方差为4,则数据 的方差为4,则数据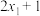 , ,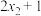 ,…, ,…,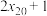 的方差为9 的方差为9 |
B.若随机变量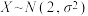 , ,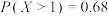 ,则 ,则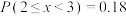 |
| C.若线性相关系数越接近1,则两个变量的线性相关性越弱 |
D.已知随机变量X服从二项分布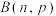 ,若 ,若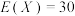 , ,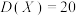 ,则 ,则 |
您最近半年使用:0次


