名校
1 . 1766年人类已经发现太阳系中的行星有金星、地球、火星、木星和土星.科学家在研究了各行星离太阳的距离(单位: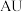 ,是天文学中计量天体之间距离的一种单位)的排列规律后,预测在火星和木星之间应该还有一颗未被发现的行星(后被命名为谷神星)存在,并按离太阳的距离从小到大列出了如下表所示的数据:
,是天文学中计量天体之间距离的一种单位)的排列规律后,预测在火星和木星之间应该还有一颗未被发现的行星(后被命名为谷神星)存在,并按离太阳的距离从小到大列出了如下表所示的数据:
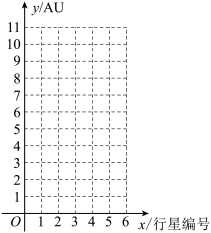
(1)为了描述行星离太阳的距离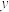 与行星编号
与行星编号 之间的关系,根据表中已有的数据画出散点图,并根据散点图的分布状况,从以下三种模型中选出你认为最符合实际的一种函数模型(直接给出结论);
之间的关系,根据表中已有的数据画出散点图,并根据散点图的分布状况,从以下三种模型中选出你认为最符合实际的一种函数模型(直接给出结论);
①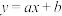 ;②
;② ;③
;③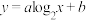 .
.
(2)根据你的选择,依表中前三组数据求出函数解析式,并用剩下的两组数据检验模型的吻合情况;(误差小于0.2的为吻合)
(3)请用你求得的模型,计算谷神星离太阳的距离.
,是天文学中计量天体之间距离的一种单位)的排列规律后,预测在火星和木星之间应该还有一颗未被发现的行星(后被命名为谷神星)存在,并按离太阳的距离从小到大列出了如下表所示的数据:行星编号 | 1 (金星) | 2 (地球) | 3 (火星) | 4 ( ) | 5 (木星) | 6 (土星) |
离太阳的距离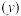 |
|
|
|
|
|
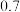
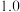
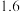

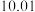 与行星编号之间的关系,根据表中已有的数据画出散点图,并根据散点图的分布状况,从以下三种模型中选出你认为最符合实际的一种函数模型(直接给出结论);
与行星编号之间的关系,根据表中已有的数据画出散点图,并根据散点图的分布状况,从以下三种模型中选出你认为最符合实际的一种函数模型(直接给出结论); ①
;②;③.(2)根据你的选择,依表中前三组数据求出函数解析式,并用剩下的两组数据检验模型的吻合情况;(误差小于0.2的为吻合)
(3)请用你求得的模型,计算谷神星离太阳的距离.
您最近一年使用:0次
2023-03-08更新
|
431次组卷
|
3卷引用:贵州省黔东南州2022-2023学年高一上学期期末文化水平测试数学试题
名校
2 . 人类已经进入大数据时代.目前,数据量已经从TB(1TB=1024GB)级别跃升到PB(1PB=1024TB),EB(1EB=1024PB)乃至ZB(1ZB=1024EB)级别.国际数据公司(IDC)的研究结果表明,2008年起全球每年产生的数据量如下表所示:
年份 | 2008 | 2009 | 2010 | 2011 | … | 2020 |
数据量(ZB) | 0.49 | 0.8 | 1.2 | 1.82 | … | 80 |
(1)设2008年为第一年,为较好地描述2008年起第
年全球生产的数据量(单位:ZB)与的关系,根据上述信息,试从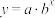 (
( ,
, 且
且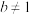 ),
), ,
, (,且)三种函数模型中选择一个,应该选哪一个更合适?(不用说明理由);
(,且)三种函数模型中选择一个,应该选哪一个更合适?(不用说明理由);(2)根据(1)中所选的函数模型,若选取2009年和2020年的数据量来估计模型中的参数,预计到哪一年,全球生产的数据量将达到2020年的100倍?
您最近一年使用:0次
2024-03-14更新
|
119次组卷
|
2卷引用:贵州省安顺市2023-2024学年高一上学期期末教学质量监测考试数学试题


